
Profile

|
Dr. Theodora Kontogianni |
Publications
Interactive4D: Interactive 4D LiDAR Segmentation
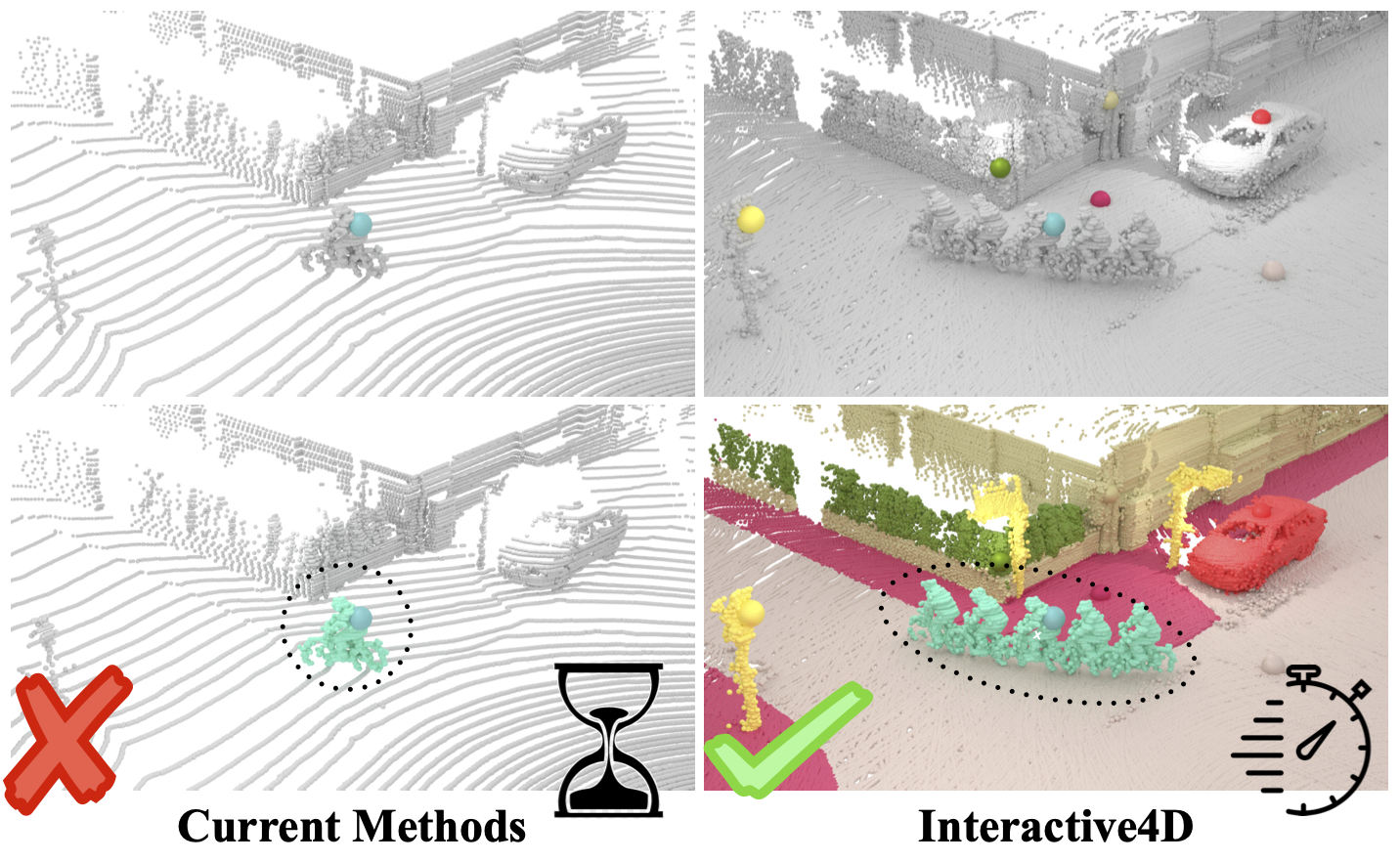
Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin.
@article{fradlin2024interactive4d,
title = {{Interactive4D: Interactive 4D LiDAR Segmentation}},
author = {Fradlin, Ilya and Zulfikar, Idil Esen and Yilmaz, Kadir and Kontogianni, Thodora and Leibe, Bastian},
journal = {arXiv preprint arXiv:2410.08206},
year = {2024}
}
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation

During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. The current best practice formulates the problem as binary classification and segments objects one at a time. The model expects the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks on regions wrongly assigned to the object. Sequentially visiting objects is wasteful since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects. Moreover, a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. Our core idea is to encode user clicks as spatial-temporal queries and enable explicit interactions between click queries as well as between them and the 3D scene through a click attention module. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different 3D point cloud datasets, AGILE3D sets a new state-of-the-art. Moreover, we also verify its practicality in real-world setups with real user studies.
@inproceedings{yue2023agile3d,
title = {{AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation}},
author = {Yue, Yuanwen and Mahadevan, Sabarinath and Schult, Jonas and Engelmann, Francis and Leibe, Bastian and Schindler, Konrad and Kontogianni, Theodora},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections

In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works employ convolutional neural networks for this task: Given an image and a set of corrections made by the user as input, they output a segmentation mask. These approaches achieve strong performance by training on large datasets but they keep the model parameters unchanged at test time. Instead, we recognize that user corrections can serve as sparse training examples and we propose a method that capitalizes on that idea to update the model parameters on-the-fly to the data at hand. Our approach enables the adaptation to a particular object and its background, to distributions shifts in a test set, to specific object classes, and even to large domain changes, where the imaging modality changes between training and testing. We perform extensive experiments on 8 diverse datasets and show: Compared to a model with frozen parameters, our method reduces the required corrections (i) by 9%-30% when distribution shifts are small between training and testing; (ii) by 12%-44% when specializing to a specific class; (iii) and by 60% and 77% when we completely change domain between training and testing.
» Show BibTeX
@inproceedings{Kontogianni20ECCV,
title={Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections},
author={ Kontogianni, Theodora and Gygli, Michael and Uijlings, Jasper and Ferrari, Vittorio},
booktitle=ECCV,
year={2020}
}
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
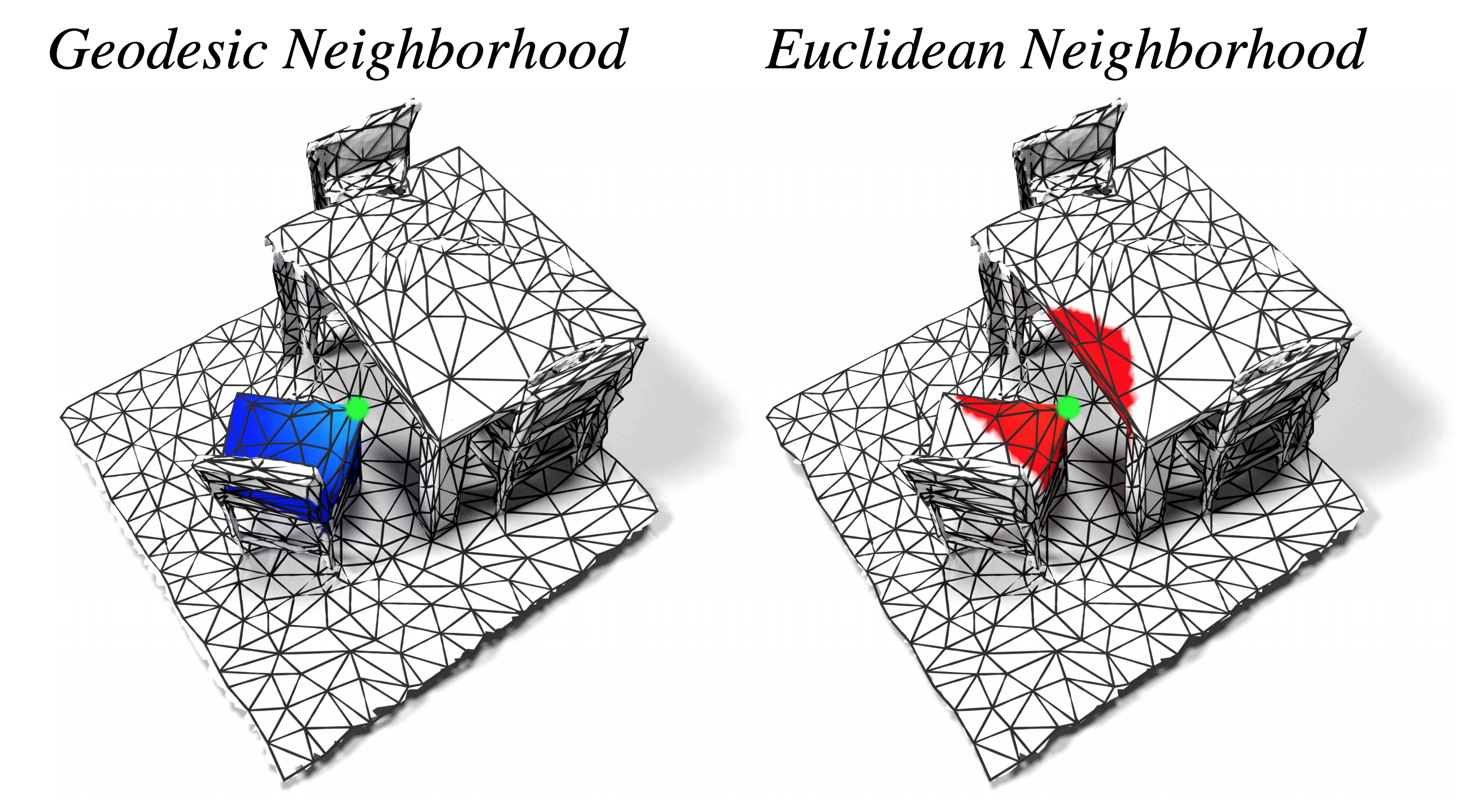
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks.
@inproceedings{Schult20CVPR,
author = {Jonas Schult* and
Francis Engelmann* and
Theodora Kontogianni and
Bastian Leibe},
title = {{DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes}},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds
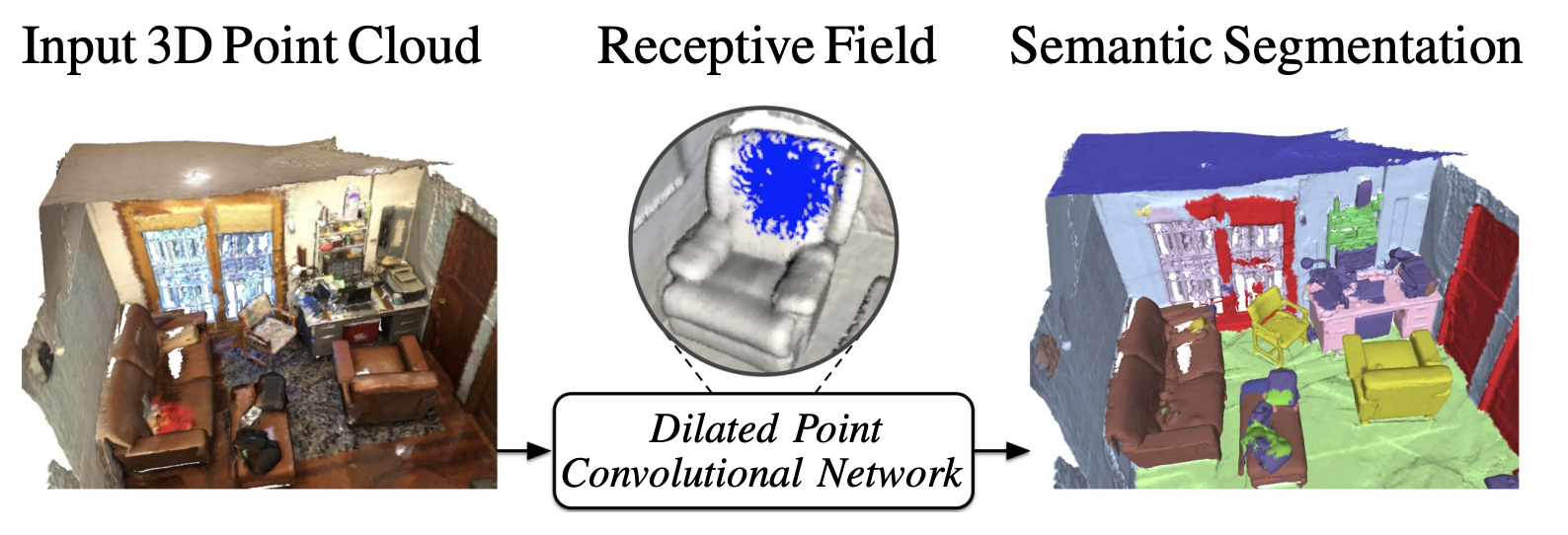
In this work, we propose Dilated Point Convolutions (DPC). In a thorough ablation study, we show that the receptive field size is directly related to the performance of 3D point cloud processing tasks, including semantic segmentation and object classification. Point convolutions are widely used to efficiently process 3D data representations such as point clouds or graphs. However, we observe that the receptive field size of recent point convolutional networks is inherently limited. Our dilated point convolutions alleviate this issue, they significantly increase the receptive field size of point convolutions. Importantly, our dilation mechanism can easily be integrated into most existing point convolutional networks. To evaluate the resulting network architectures, we visualize the receptive field and report competitive scores on popular point cloud benchmarks.
@inproceedings{Engelmann20ICRA,
author = {Engelmann, Francis and Kontogianni, Theodora and Leibe, Bastian},
title = {{Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds}},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2020}
}
3D-BEVIS: Birds-Eye-View Instance Segmentation
Recent deep learning models achieve impressive results on 3D scene analysis tasks by operating directly on unstructured point clouds. A lot of progress was made in the field of object classification and semantic segmentation. However, the task of instance segmentation is less explored. In this work, we present 3D-BEVIS, a deep learning framework for 3D semantic instance segmentation on point clouds. Following the idea of previous proposal-free instance segmentation approaches, our model learns a feature embedding and groups the obtained feature space into semantic instances. Current point-based methods scale linearly with the number of points by processing local sub-parts of a scene individually. However, to perform instance segmentation by clustering, globally consistent features are required. Therefore, we propose to combine local point geometry with global context information from an intermediate bird's-eye view representation.
@inproceedings{ElichGCPR19,
title = {{3D-BEVIS: Birds-Eye-View Instance Segmentation}},
author = {Elich, Cathrin and Engelmann, Francis and Schult, Jonas and Kontogianni, Theodora and Leibe, Bastian},
booktitle = {{German Conference on Pattern Recognition (GCPR)}},
year = {2019}
}
Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds
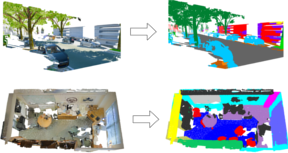
In this paper, we present a deep learning architecture which addresses the problem of 3D semantic segmentation of unstructured point clouds. Compared to previous work, we introduce grouping techniques which define point neighborhoods in the initial world space and the learned feature space. Neighborhoods are important as they allow to compute local or global point features depending on the spatial extend of the neighborhood. Additionally, we incorporate dedicated loss functions to further structure the learned point feature space: the pairwise distance loss and the centroid loss. We show how to apply these mechanisms to the task of 3D semantic segmentation of point clouds and report state-of-the-art performance on indoor and outdoor datasets.
@inproceedings{3dsemseg_ECCVW18,
author = {Francis Engelmann and
Theodora Kontogianni and
Jonas Schult and
Bastian Leibe},
title = {Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} European Conference on Computer Vision, GMDL Workshop, {ECCV}},
year = {2018}
}
Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
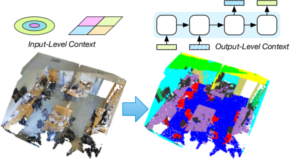
Deep learning approaches have made tremendous progress in the field of semantic segmentation over the past few years. However, most current approaches operate in the 2D image space. Direct semantic segmentation of unstructured 3D point clouds is still an open research problem. The recently proposed PointNet architecture presents an interesting step ahead in that it can operate on unstructured point clouds, achieving decent segmentation results. However, it subdivides the input points into a grid of blocks and processes each such block individually. In this paper, we investigate the question how such an architecture can be extended to incorporate larger-scale spatial context. We build upon PointNet and propose two extensions that enlarge the receptive field over the 3D scene. We evaluate the proposed strategies on challenging indoor and outdoor datasets and show improved results in both scenarios.
» Show BibTeX
@inproceedings{3dsemseg_ICCVW17,
author = {Francis Engelmann and
Theodora Kontogianni and
Alexander Hermans and
Bastian Leibe},
title = {Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} International Conference on Computer Vision, 3DRMS Workshop, {ICCV}},
year = {2017}
}
Incremental Object Discovery in Time-Varying Image Collections
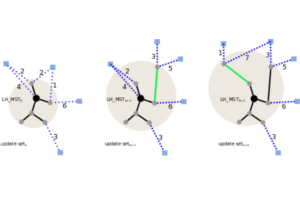
In this paper, we address the problem of object discovery in time-varying, large-scale image collections. A core part of our approach is a novel Limited Horizon Minimum Spanning Tree (LH-MST) structure that closely approximates the Minimum Spanning Tree at a small fraction of the latter’s computational cost. Our proposed tree structure can be created in a local neighborhood of the matching graph during image retrieval and can be efficiently updated whenever the image database is extended. We show how the LH-MST can be used within both single-link hierarchical agglomerative clustering and the Iconoid Shift framework for object discovery in image collections, resulting in significant efficiency gains and making both approaches capable of incremental clustering with online updates. We evaluate our approach on a dataset of 500k images from the city of Paris and compare its results to the batch version of both clustering algorithms.
