
Profile

|
M.Sc. Jens Piekenbrinck |
Publications
Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization
3D Gaussian Splatting has recently emerged as a powerful tool for fast and accurate novel-view synthesis from a set of posed input images. However, like most novel-view synthesis approaches, it relies on accurate camera pose information, limiting its applicability in real-world scenarios where acquiring accurate camera poses can be challenging or even impossible. We propose an extension to the 3D Gaussian Splatting framework by optimizing the extrinsic camera parameters with respect to photometric residuals. We derive the analytical gradients and integrate their computation with the existing high-performance CUDA implementation. This enables downstream tasks such as 6-DoF camera pose estimation as well as joint reconstruction and camera refinement. In particular, we achieve rapid convergence and high accuracy for pose estimation on real-world scenes. Our method enables fast reconstruction of 3D scenes without requiring accurate pose information by jointly optimizing geometry and camera poses, while achieving state-of-the-art results in novel-view synthesis. Our approach is considerably faster to optimize than most com- peting methods, and several times faster in rendering. We show results on real-world scenes and complex trajectories through simulated environments, achieving state-of-the-art results on LLFF while reducing runtime by two to four times compared to the most efficient competing method. Source code will be available at https://github.com/Schmiddo/noposegs.
RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout
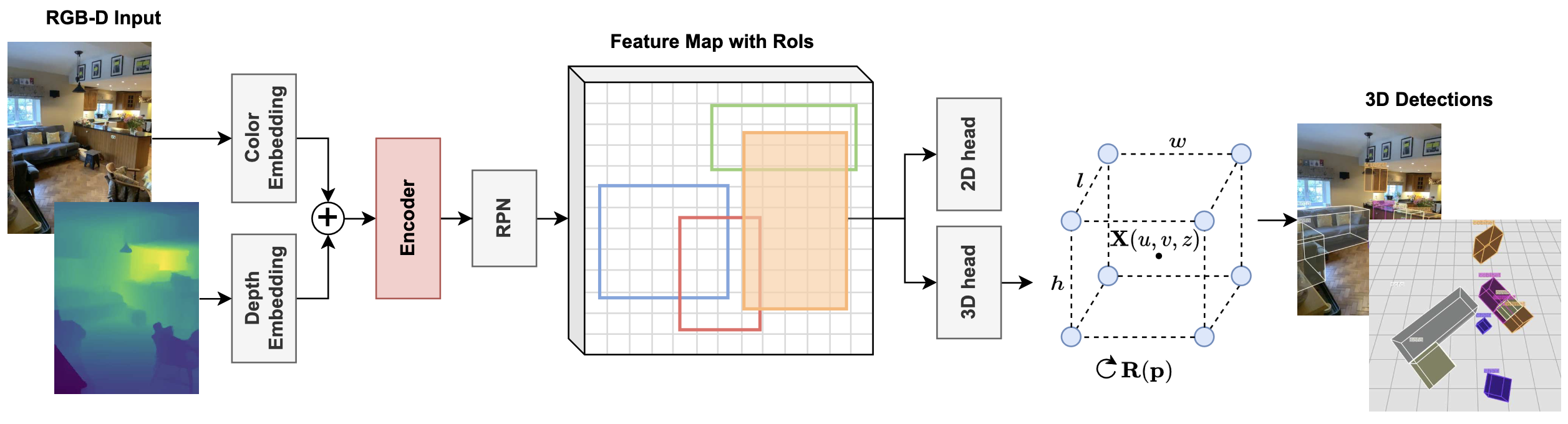
In this paper we create an RGB-D 3D object detector targeted at indoor robotics use cases where one modality may be unavailable due to a specific sensor setup or a sensor failure. We incorporate RGB and depth fusion into the recent Cube R-CNN framework with support for selective modality dropout. To train this model we augment the Omni3DIN dataset with depth information leading to a diverse dataset for 3D object detection in indoor scenes. In order to leverage strong pretrained networks we investigate the viability of Transformer-based backbones (Swin ViT) as an alternative to the currently popular CNN-based DLA backbone. We show that these Transformer-based image models work well based on our early-fusion approach and propose a modality dropout scheme to avoid the disregard of any modality during training facilitating selective modality dropout during inference. In extensive experiments our proposed RGB-D Cube R-CNN outperforms an RGB-only Cube R-CNN baseline by a significant margin on the task of indoor object detection. Additionally we observe a slight performance boost from the RGB-D training when inferring on only one modality which could for example be valuable in robotics applications with a reduced or unreliable sensor set.
@InProceedings{RGB_D_Cube_RCNN_2024_CVPRW,
author = {Piekenbrinck, Jens and Hermans, Alexander and Vaskevicius, Narunas and Linder, Timm and Leibe, Bastian},
title = {{RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
year = {2024},
}
