
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
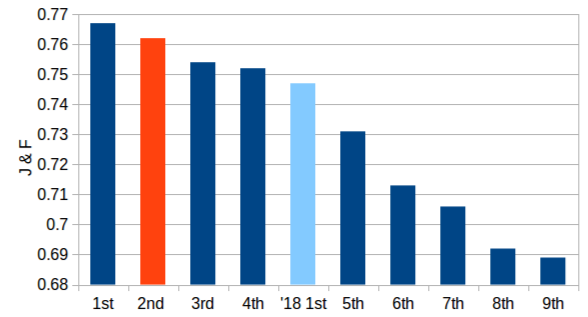
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
