
Profile

|
Dr. István Sárándi |
Update: Since March 2023, I'm a postdoctoral researcher in the Real Virtual Humans group at the University of Tübingen! See my personal site for the latest information.
My research interests lie in the automated visual analysis of humans, especially for applications such as human-robot interaction and collaborative robotics. My focus is on estimating articulated 3D body pose using deep learning methods.
Supervised Students
- Markus Knoche (master thesis Volumetric Feature Transformation for Pose-Conditioned Human Image Synthesis, 2020; CVPRW'20 paper)
- Yinglun Liu (master thesis Monocular 3D Human Pose Estimation using Depth as Privileged Information, 2021)
- Stefan Erlbeck (master thesis Temporal Modeling of 3D Human Poses in Multi-Person Interaction Scenarios, 2022)
- Thanh Nguyen (student assistant)
Teaching
- Computer Vision: Summer 2020 | Summer 2019
- Deep Learning Laboratory: Summer 2021
- Seminar Computer Vision and Machine Learning
- Supervision: WS21 | WS20 | SS20 | WS19 | SS19 | SS18
- Organization: Winter 2021/22 | Winter 2020/21
- Introduction to Computer Science: Winter 2017/18
Publications
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
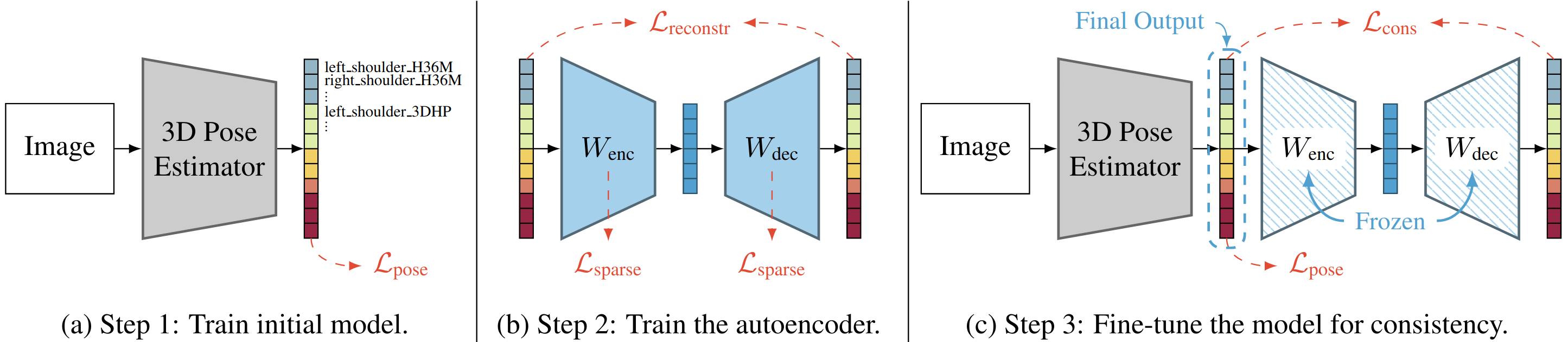
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
» Show BibTeX
@inproceedings{Sarandi23WACV,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023},
}
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation

Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code is publicly available to facilitate further research.
Winning submission at the ECCV 2020 3D Poses in the Wild Challenge
» Show BibTeX
@article{Sarandi21metrabs,
title={{MeTRAbs:} Metric-Scale Truncation-Robust Heatmaps for Absolute {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
journal={IEEE Transactions on Biometrics, Behavior, and Identity Science},
year={2021},
volume={3},
number={1},
pages={16--30}
}
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
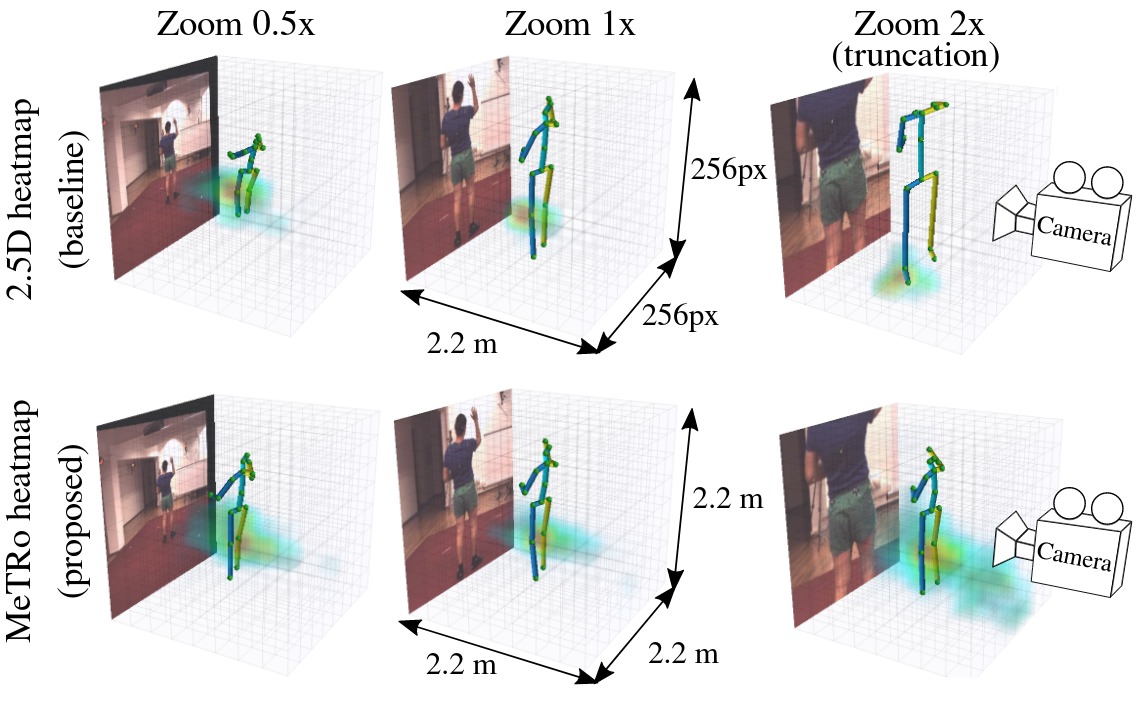
Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research.
See also the extended journal version of this paper at https://vision.rwth-aachen.de/publication/00203 (journal version preferred for citation).
» Show BibTeX
@inproceedings{Sarandi20metro,
title={Metric-Scale Truncation-Robust Heatmaps for {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE International Conference on Automatic Face and Gesture Recognition (FG)},
year={2020}
}
Reposing Humans by Warping 3D Features
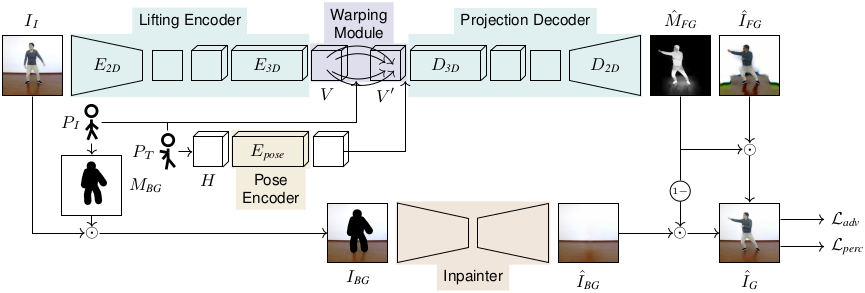
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.
» Show BibTeX
@inproceedings{Knoche20reposing,
author = {Markus Knoche and Istv\'an S\'ar\'andi and Bastian Leibe},
title = {Reposing Humans by Warping {3D} Features},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2020}
}
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
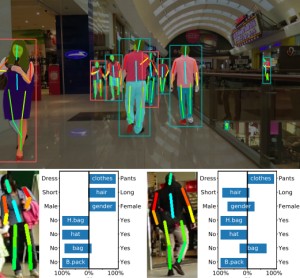
We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
@inproceedings{Pfeiffer19GCPR,
title = {Visual Person Understanding Through Multi-task and Multi-dataset Learning},
author = {Kilian Pfeiffer and Alexander Hermans and Istv\'{a}n S\'{a}r\'{a}ndi and Mark Weber and Bastian Leibe},
booktitle = {German Conference on Pattern Recognition (GCPR)},
date = {2019}
}
How Robust is 3D Human Pose Estimation to Occlusion?
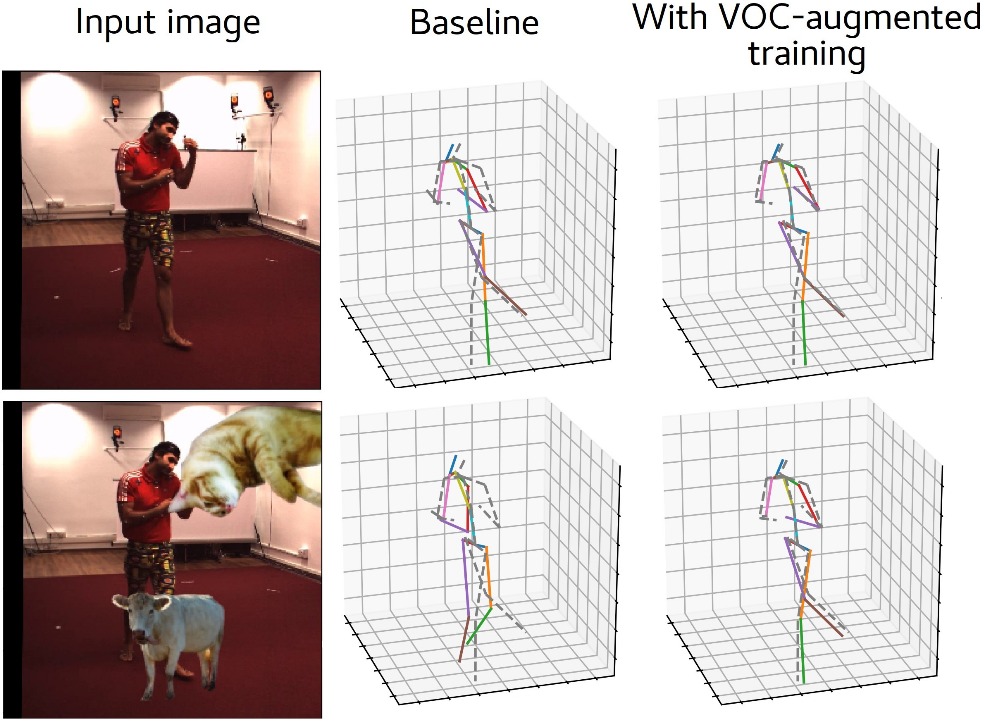
Occlusion is commonplace in realistic human-robot shared environments, yet its effects are not considered in standard 3D human pose estimation benchmarks. This leaves the question open: how robust are state-of-the-art 3D pose estimation methods against partial occlusions? We study several types of synthetic occlusions over the Human3.6M dataset and find a method with state-of-the-art benchmark performance to be sensitive even to low amounts of occlusion. Addressing this issue is key to progress in applications such as collaborative and service robotics. We take a first step in this direction by improving occlusion-robustness through training data augmentation with synthetic occlusions. This also turns out to be an effective regularizer that is beneficial even for non-occluded test cases.
@inproceedings{Sarandi18IROSW,
title={How Robust is {3D} Human Pose Estimation to Occlusion?},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems Workshops (IROSW)},
year={2018}
}
Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation
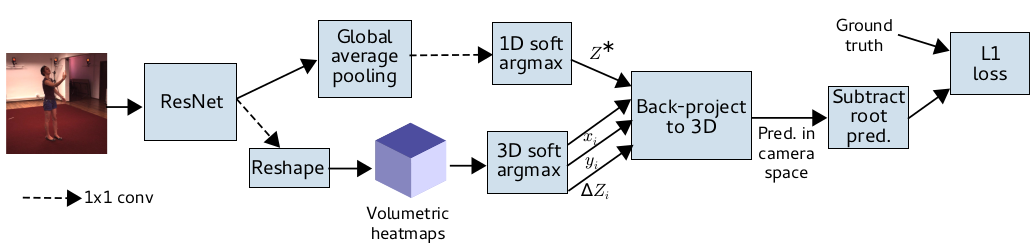
In this paper we present our winning entry at the 2018 ECCV PoseTrack Challenge on 3D human pose estimation. Using a fully-convolutional backbone architecture, we obtain volumetric heatmaps per body joint, which we convert to coordinates using soft-argmax. Absolute person center depth is estimated by a 1D heatmap prediction head. The coordinates are back-projected to 3D camera space, where we minimize the L1 loss. Key to our good results is the training data augmentation with randomly placed occluders from the Pascal VOC dataset. In addition to reaching first place in the Challenge, our method also surpasses the state-of-the-art on the full Human3.6M benchmark when considering methods that use no extra pose datasets in training. Code for applying synthetic occlusions is availabe at https://github.com/isarandi/synthetic-occlusion.
» Show BibTeX
@article{Sarandi18synthocc,
author = {S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
title = {Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 {ECCV PoseTrack Challenge} on {3D} Human Pose Estimation},
journal={arXiv preprint arXiv:1809.04987},
year = {2018}
}
Pedestrian Line Counting by Probabilistic Combination of Flow and Appearance Information
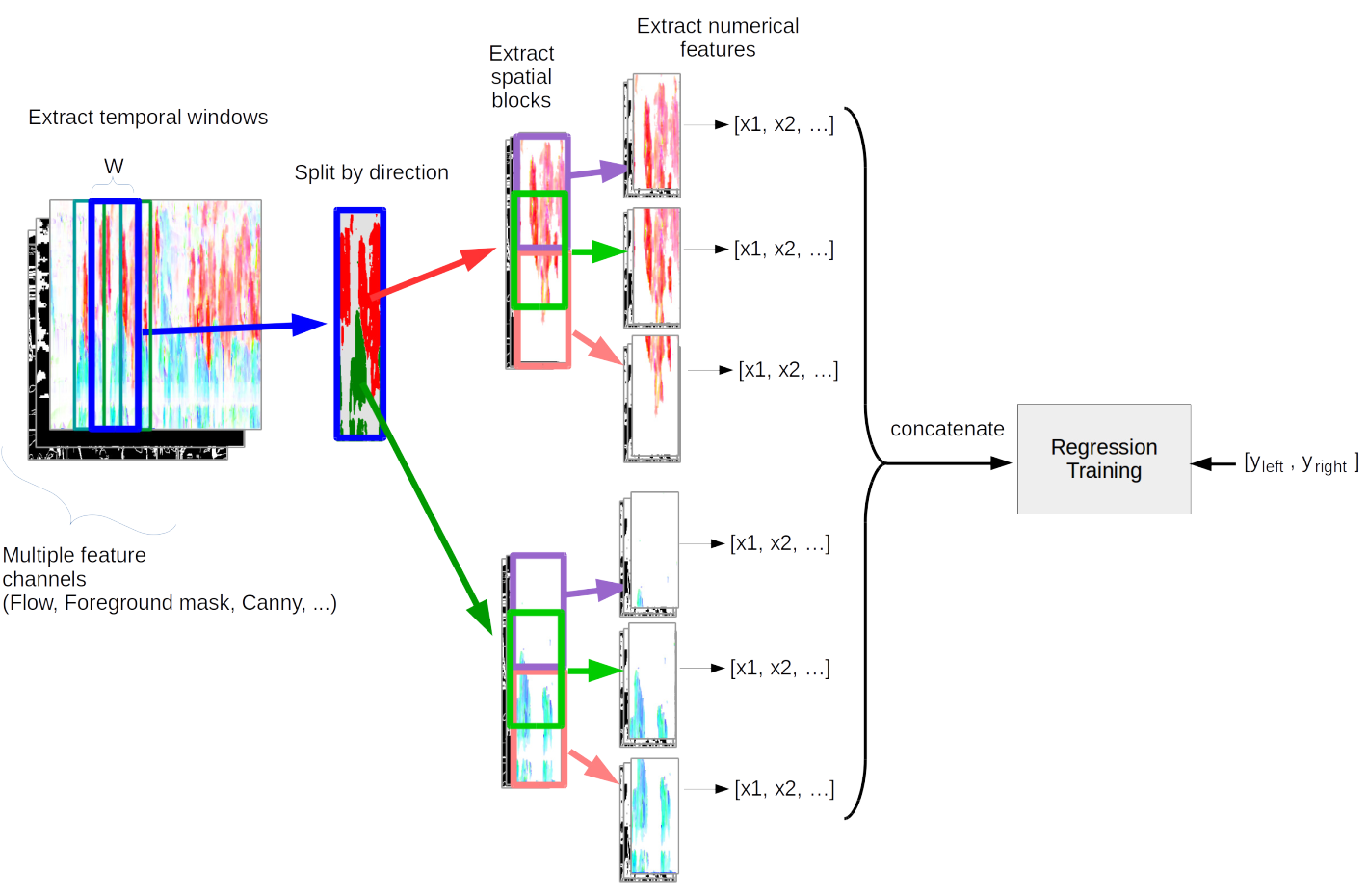
In this thesis we examine the task of estimating how many pedestrians cross a given line in a surveillance video, in the presence of high occlusion and dense crowds. We show that a prior, blob-based pedestrian line counting method fails on our newly annotated private dataset, which is more challenging than those used in the literature.
We propose a new spatiotemporal slice-based method that works with simple low-level features based on optical flow, background subtraction and edge detection and show that it produces good results on the new dataset. Furthermore, presumably due to the very simple and general nature of the features we use, the method also performs well on the popular UCSD vidd dataset without additional hyperparameter tuning, showing the robustness of our approach.
We design new evaluation measures that generalize the precision and recall used in information retrieval and binary classification to continuous, instantaneous pedestrian flow estimations and we argue that they are better suited to this task than currently used measures.
We also consider the relations between pedestrian region counting and line counting by comparing the output of a region counting method with the counts that we derive from line counting. Finally we show a negative result, where a probabilistic method for combining line and region counter outputs does not lead to the hoped result of mutually improved counters.
Quantitative Conjunctival Provocation Test for Controlled Clinical Trials
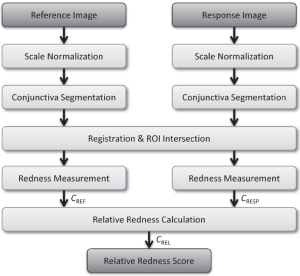
The conjunctival provocation test (CPT) is a diagnostic procedure for the assessment of allergic diseases. Photographs are taken before and after provocation increasing the redness of the conjunctiva due to hyperemia. We propose and evaluate an automatic image processing pipeline for objective and quantitative CPT. After scale normalization based on intrinsic image features, the conjunctiva region of interest (ROI) is segmented combining thresholding, edge detection and Hough transform. Redness of the ROI is measured from 0 to 1 by the average pixel redness, which is defined by truncated projection in HSV space. In total, 92 images from an observational diagnostic study are processed for evaluation. The database contains images from two visits for assessment of the test-retest reliability (46 images per visit). All images were successfully processed by the algorithm. The relative redness increment correlates between the two visits with Pearson's r=0.672 (p<.001). Linear correlation of the automatic measure is larger than the manual measure (r=0.59). This indicates a higher reproducibility and stability of the automatic method. We presented a robust and effective way to objectify CPT. The algorithm operates on low resolution, is fast and requires no manual input. Quantitative CPT measures can now be established as surrogate endpoint in controlled clinical trials.
@article{Sarandi14MIM,
title={Quantitative conjunctival provocation test for controlled clinical trials},
author={S\'ar\'andi, I and Cla{\ss}en, DP and Astvatsatourov, A and Pfaar, O and Klimek, L and M{\"o}sges, R and Deserno, TM},
journal={Methods of information in medicine},
volume={53},
number={04},
pages={238--244},
year={2014},
publisher={Schattauer GmbH}
}
Towards Quantitative Assessment of Calciphylaxis
Calciphylaxis is a rare disease that has devastating conditions associated with high morbidity and mortality. Calciphylaxis is characterized by systemic medial calcification of the arteries yielding necrotic skin ulcerations. In this paper, we aim at supporting the installation of multi-center registries for calciphylaxis, which includes a photographic documentation of skin necrosis. However, photographs acquired in different centers under different conditions using different equipment and photographers cannot be compared quantitatively. For normalization, we use a simple color pad that is placed into the field of view, segmented from the image, and its color fields are analyzed. In total, 24 colors are printed on that scale. A least-squares approach is used to determine the affine color transform. Furthermore, the card allows scale normalization. We provide a case study for qualitative assessment. In addition, the method is evaluated quantitatively using 10 images of two sets of different captures of the same necrosis. The variability of quantitative measurements based on free hand photography is assessed regarding geometric and color distortions before and after our simple calibration procedure. Using automated image processing, the standard deviation of measurements is significantly reduced. The coefficients of variations yield 5-20% and 2-10% for geometry and color, respectively. Hence, quantitative assessment of calciphylaxis becomes practicable and will impact a better understanding of this rare but fatal disease.
