
Profile

|
Dr. Patrick Sudowe |
Research
My work at the chair has resulted in two public releases:
-
GroundHOG project - an optimized GPU implementation of the HOG detector with further optimizations through geometric scene constraints ICVS Paper.
-
Pedestrian attribute dataset Parse27k
Teaching
- Teaching Assistant, Machine Learning, Summer Semester '11
- Teaching Assistant, Advanced Machine Learning, Winter Semester '12-'13
- Seminar Organizer, Summer 2015.
- Seminar Advisor, regularly advised students in the group's seminar 'Current Topics in Computer Vision and Machine Learning'
Students
- Johannes Frohn - master thesis - Efficient Features for Histogram Intersection Kernel based Object Detection
- Vladislav Supalov - bachelor thesis - Local Binary Patterns for Pedestrian Detection
- Archana Kumari - master thesis - Visual Trait Classification
- Francis Engelmann - master thesis - Multiple Target Tracking for Marker-less Augmented Reality
- Jakob Bauer - bachelor thesis - Multi-Channel Feeatures for Pedestrian Attribute Recognition
- Hannah Spitzer - master thesis - Deep Learning for Pedestrian Attribute Recognition
Publications
PatchIt: Self-supervised Network Weight Initialization for Fine-grained Recognition
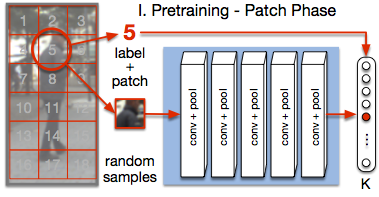
ConvNet training is highly sensitive to initialization of the weights. A widespread approach is to initialize the network with weights trained for a different task, an auxiliary task. The ImageNet-based ILSVRC classification task is a very popular choice for this, as it has shown to produce powerful feature representations applicable to a wide variety of tasks. However, this creates a significant entry barrier to exploring non-standard architectures. In this paper, we propose a self-supervised pretraining, the PatchTask, to obtain weight initializations for fine-grained recognition problems, such as person attribute recognition, pose estimation, or action recognition. Our pretraining allows us to leverage additional unlabeled data from the same source, which is often readily available, such as detection bounding boxes. We experimentally show that our method outperforms a standard random initialization by a considerable margin and closely matches the ImageNet-based initialization.
@InProceedings{Sudowe16BMVC,
author = {Patrick Sudowe and Bastian Leibe},
title = {{PatchIt: Self-Supervised Network Weight Initialization for Fine-grained Recognition}},
booktitle = BMVC,
year = {2016}
}
Person Attribute Recognition with a Jointly-trained Holistic CNN Model
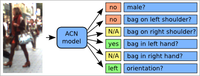
This paper addresses the problem of human visual attribute recognition, i.e., the prediction of a fixed set of semantic attributes given an image of a person. Previous work often considered the different attributes independently from each other, without taking advantage of possible dependencies between them. In contrast, we propose a method to jointly train a CNN model for all attributes that can take advantage of those dependencies, considering as input only the image without additional external pose, part or context information. We report detailed experiments examining the contribution of individual aspects, which yields beneficial insights for other researchers. Our holistic CNN achieves superior performance on two publicly available attribute datasets improving on methods that additionally rely on pose-alignment or context. To support further evaluations, we present a novel dataset, based on realistic outdoor video sequences, that contains more than 27,000 pedestrians annotated with 10 attributes. Finally, we explore design options to embrace the N/A labels inherently present in this task.
@InProceedings{PARSE27k,
author = {Patrick Sudowe and Hannah Spitzer and Bastian Leibe},
title = {{Person Attribute Recognition with a Jointly-trained Holistic CNN Model}},
booktitle = {ICCV'15 ChaLearn Looking at People Workshop},
year = {2015},
}
Multiple Target Tracking for Marker-less Augmented Reality
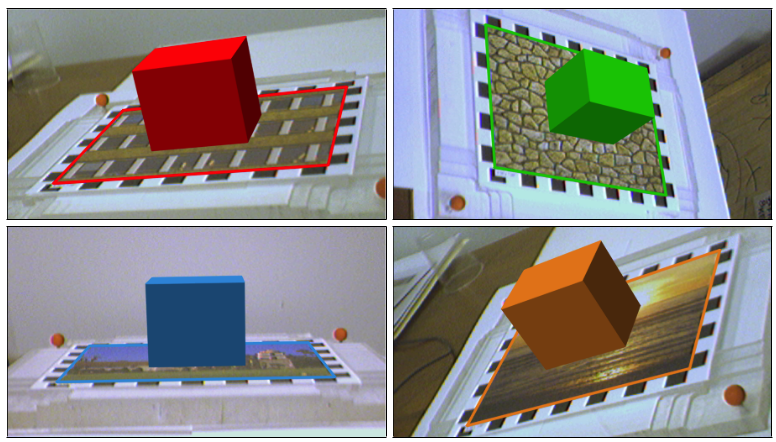
In this work, we implemented an AR framework for planar targets based on the ORB feature-point descriptor. The main components of the framework are a detector, a tracker and a graphical overlay. The detector returns a homography that maps the model- image onto the target in the camera-image. The homography is estimated from a set of feature-point correspondences using the Direct Linear Transform (DLT) algorithm and Levenberg-Marquardt (LM) optimization. The outliers in the set of feature-point correspondences are removed using RANSAC. The tracker is based on the Kalman filter, which applies a consistent dynamic movement on the target. In a hierarchical matching scheme, we extract additional matches from consecutive frames and perspectively transformed model-images, which yields more accurate and jitter-free homography estimations. The graphical overlay computes the six-degree-of-freedom (6DoF) pose from the estimated homography. Finally, to visualize the computed pose, we draw a cube on the surface of the tracked target. In the evaluation part, we analyze the performance of our system by looking at the accuracy of the estimated homography and the ratio of correctly tracked frames. The evaluation is based on the ground truth provided by two datasets. We evaluate most components of the framework under different target movements and lighting conditions. In particular, we proof that our framework is robust against considerable perspective distortion and show the benefit of using the hierarchical matching scheme to minimize jitter and improve accuracy.
A Flexible ASIP Architecture for Connected Components Labeling in Embedded Vision Applications
Real-time identification of connected regions of pixels in large (e.g. FullHD) frames is a mandatory and expensive step in many computer vision applications that are becoming increasingly popular in embedded mobile devices such as smart-phones, tablets and head mounted devices. Standard off-the-shelf embedded processors are not yet able to cope with the performance/flexibility trade-offs required by such applications. Therefore, in this work we present an Application Specific Instruction Set Processor (ASIP) tailored to concurrently execute thresholding, connected components labeling and basic feature extraction of image frames. The proposed architecture is capable to cope with frame complexities ranging from QCIF to FullHD frames with 1 to 4 bytes-per-pixel formats, while achieving an average frame rate of 30 frames-per-second (fps). Synthesis was performed for a standard 65nm CMOS library, obtaining an operating frequency of 350MHz and 2.1mm2 area. Moreover, evaluations were conducted both on typical and synthetic data sets, in order to thoroughly assess the achievable performance. Finally, an entire planar-marker based augmented reality application was developed and simulated for the ASIP.
Real-Time Multi-Person Tracking with Time-Constrained Detection
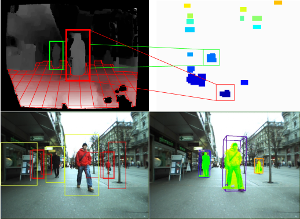
This paper presents a robust real-time multi-person tracking framework for busy street scenes. Tracking-by-detection approaches have recently been successfully applied to this task. However, their run-time is still limited by the computationally expensive object detection component. In this paper, we therefore consider the problem of making best use of an object detector with a fixed and very small time budget. The question we ask is: given a fixed time budget that allows for detector-based verification of k small regions-of-interest (ROIs) in the image, what are the best regions to attend to in order to obtain stable tracking performance? We address this problem by applying a statistical Poisson process model in order to rate the urgency by which individual ROIs should be attended to. These ROIs are initially extracted from a 3D depth-based occupancy map of the scene and are then tracked over time. This allows us to balance the system resources in order to satisfy the twin goals of detecting newly appearing objects, while maintaining the quality of existing object trajectories.
@inproceedings{DBLP:conf/bmvc/MitzelSL11,
author = {Dennis Mitzel and
Patrick Sudowe and
Bastian Leibe},
title = {Real-Time Multi-Person Tracking with Time-Constrained Detection},
booktitle = {British Machine Vision Conference, {BMVC} 2011, Dundee, UK, August
29 - September 2, 2011. Proceedings},
pages = {1--11},
year = {2011},
crossref = {DBLP:conf/bmvc/2011},
url = {http://dx.doi.org/10.5244/C.25.104},
doi = {10.5244/C.25.104},
timestamp = {Wed, 24 Apr 2013 17:19:07 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/bmvc/MitzelSL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real Time Vision Based Multi-person Tracking for Mobile Robotics and Intelligent Vehicles
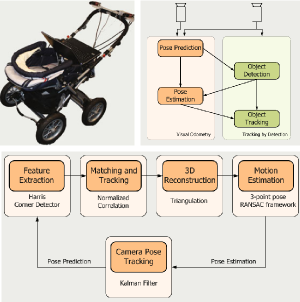
In this paper, we present a real-time vision-based multiperson tracking system working in crowded urban environments. Our approach combines stereo visual odometry estimation, HOG pedestrian detection, and multi-hypothesis tracking-by-detection to a robust tracking framework that runs on a single laptop with a CUDA-enabled graphics card. Through shifting the expensive computations to the GPU and making extensive use of scene geometry constraints we could build up a mobile system that runs with 10Hz. We experimentally demonstrate on several challenging sequences that our approach achieves competitive tracking performance.
@inproceedings{DBLP:conf/icira/MitzelFSZL11,
author = {Dennis Mitzel and
Georgios Floros and
Patrick Sudowe and
Benito van der Zander and
Bastian Leibe},
title = {Real Time Vision Based Multi-person Tracking for Mobile Robotics and
Intelligent Vehicles},
booktitle = {Intelligent Robotics and Applications - 4th International Conference,
{ICIRA} 2011, Aachen, Germany, December 6-8, 2011, Proceedings, Part
{II}},
pages = {105--115},
year = {2011},
crossref = {DBLP:conf/icira/2011-2},
url = {http://dx.doi.org/10.1007/978-3-642-25489-5_11},
doi = {10.1007/978-3-642-25489-5_11},
timestamp = {Fri, 02 Dec 2011 12:36:17 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/icira/MitzelFSZL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video

We systematically investigate how geometric constraints can be used for efficient sliding-window object detection. Starting with a general characterization of the space of sliding-window locations that correspond to geometrically valid object detections, we derive a general algorithm for incorporating ground plane constraints directly into the detector computation. Our approach is indifferent to the choice of detection algorithm and can be applied in a wide range of scenarios. In particular, it allows to effortlessly combine multiple different detectors and to automatically compute regions-of-interest for each of them. We demonstrate its potential in a fast CUDA implementation of the HOG detector and show that our algorithm enables a factor 2-4 speed improvement on top of all other optimizations.
Bibtex:
@InProceedings{Sudowe11ICVS,
author = {P. Sudowe and B. Leibe},
title = {{Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video}},
booktitle = {{International Conference on Computer Vision Systems (ICVS'11)}},
OPTpages = {},
year = {2011},
}
