
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
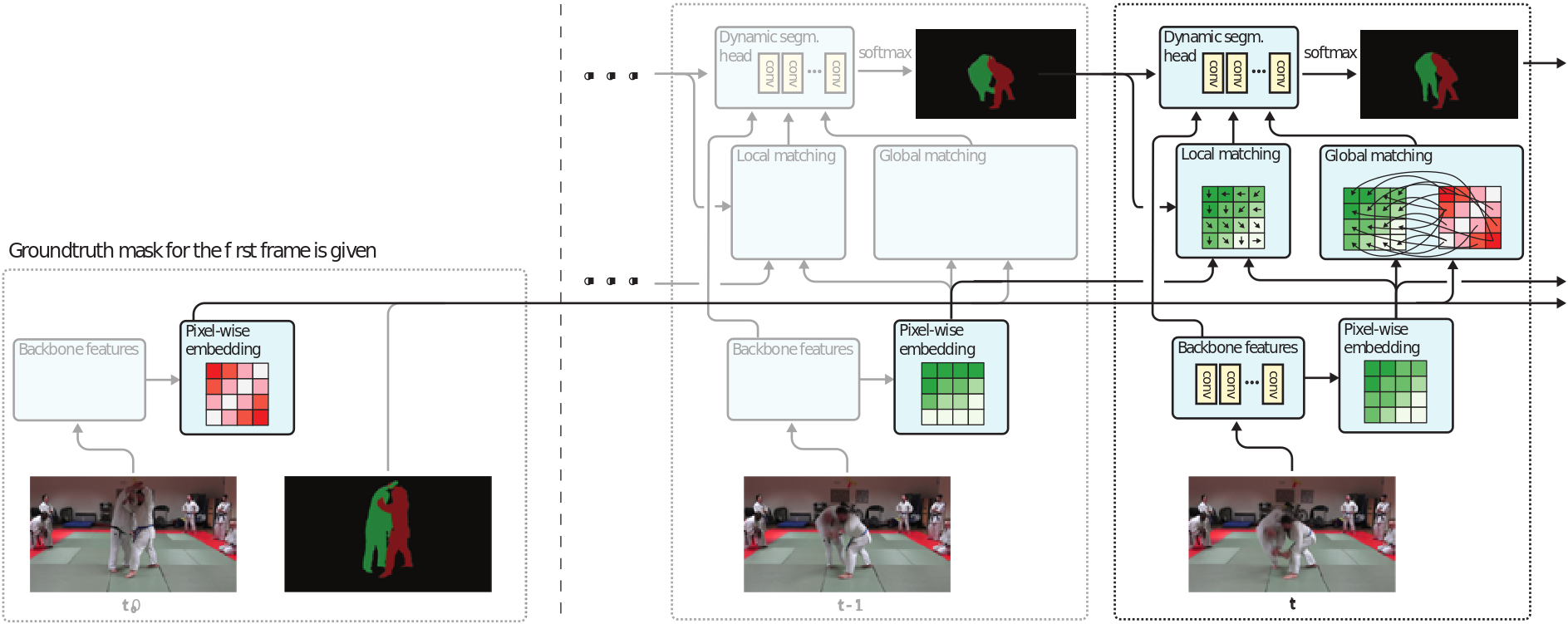
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
@inproceedings{Voigtlaender19CVPR,
title={{FEELVOS}: Fast End-to-End Embedding Learning for Video Object Segmentation},
author={Paul Voigtlaender and Yuning Chai and Florian Schroff and Hartwig Adam and Bastian Leibe and Liang-Chieh Chen},
booktitle={CVPR},
year={2019}
}
