
Profile

|
M.Sc. Sabarinath Mahadevan |
Publications
Point-VOS: Pointing Up Video Object Segmentation

Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation

During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. The current best practice formulates the problem as binary classification and segments objects one at a time. The model expects the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks on regions wrongly assigned to the object. Sequentially visiting objects is wasteful since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects. Moreover, a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. Our core idea is to encode user clicks as spatial-temporal queries and enable explicit interactions between click queries as well as between them and the 3D scene through a click attention module. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different 3D point cloud datasets, AGILE3D sets a new state-of-the-art. Moreover, we also verify its practicality in real-world setups with real user studies.
@inproceedings{yue2023agile3d,
title = {{AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation}},
author = {Yue, Yuanwen and Mahadevan, Sabarinath and Schult, Jonas and Engelmann, Francis and Leibe, Bastian and Schindler, Konrad and Kontogianni, Theodora},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
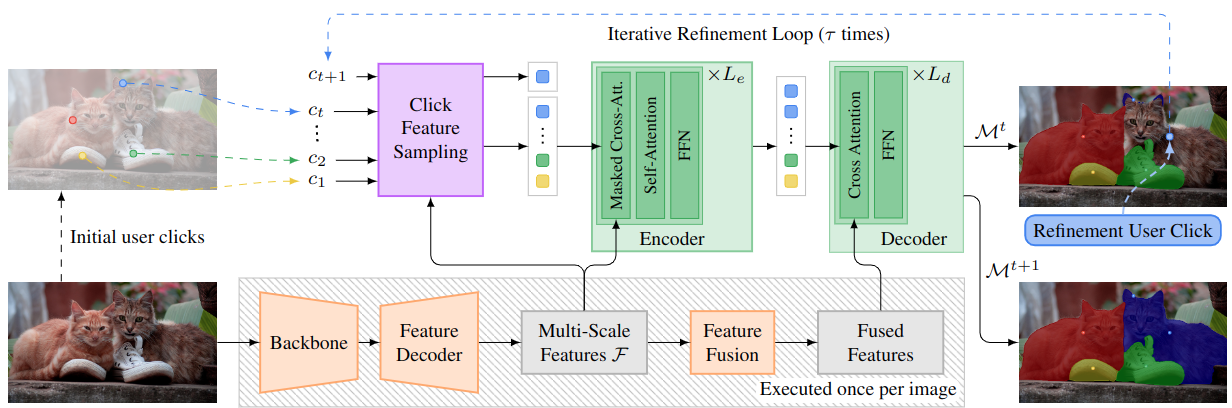
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
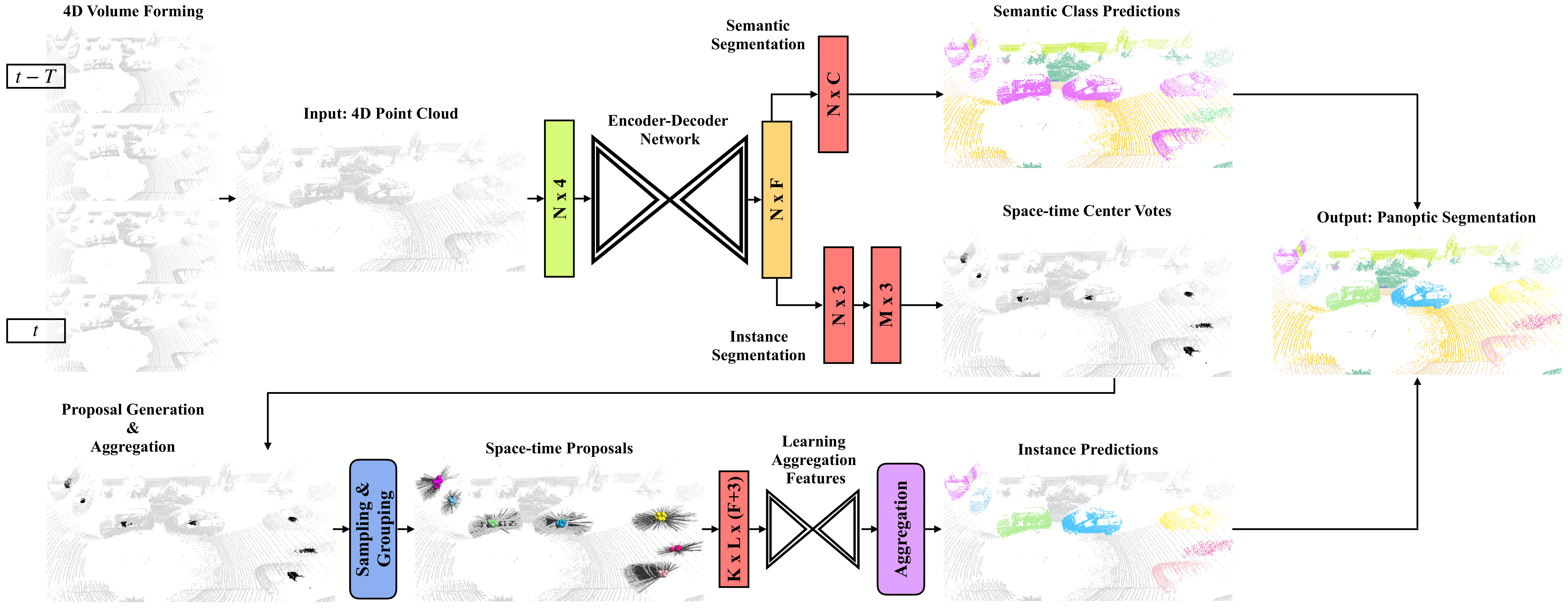
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at:https://github.com/LarsKreuzberg/4D-StOP
STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos

Existing methods for instance segmentation in videos typically involve multi-stage pipelines that follow the tracking-by-detection paradigm and model a video clip as a sequence of images. Multiple networks are used to detect objects in individual frames, and then associate these detections over time. Hence, these methods are often non-end-to-end trainable and highly tailored to specific tasks. In this paper, we propose a different approach that is well-suited to a variety of tasks involving instance segmentation in videos. In particular, we model a video clip as a single 3D spatio-temporal volume, and propose a novel approach that segments and tracks instances across space and time in a single stage. Our problem formulation is centered around the idea of spatio-temporal embeddings which are trained to cluster pixels belonging to a specific object instance over an entire video clip. To this end, we introduce (i) novel mixing functions that enhance the feature representation of spatio-temporal embeddings, and (ii) a single-stage, proposal-free network that can reason about temporal context. Our network is trained end-to-end to learn spatio-temporal embeddings as well as parameters required to cluster these embeddings, thus simplifying inference. Our method achieves state-of-the-art results across multiple datasets and tasks.
» Show BibTeX
@inproceedings{AtharMahadevan20ECCV,
title={STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos},
author={Athar, Ali and Mahadevan, Sabarinath and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle=ECCV,
year={2020}
}
Making a Case for 3D Convolutions for Object Segmentation in Videos

The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks.
» Show BibTeX
@inproceedings{Mahadevan20BMVC,
title={Making a Case for 3D Convolutions for Object Segmentation in Videos},
author={Mahadevan, Sabarinath and Athar, Ali and O{\v{s}}ep, Aljo{\v{s}}a and Hennen, Sebastian and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle={BMVC},
year={2020}
}
Iteratively Trained Interactive Segmentation
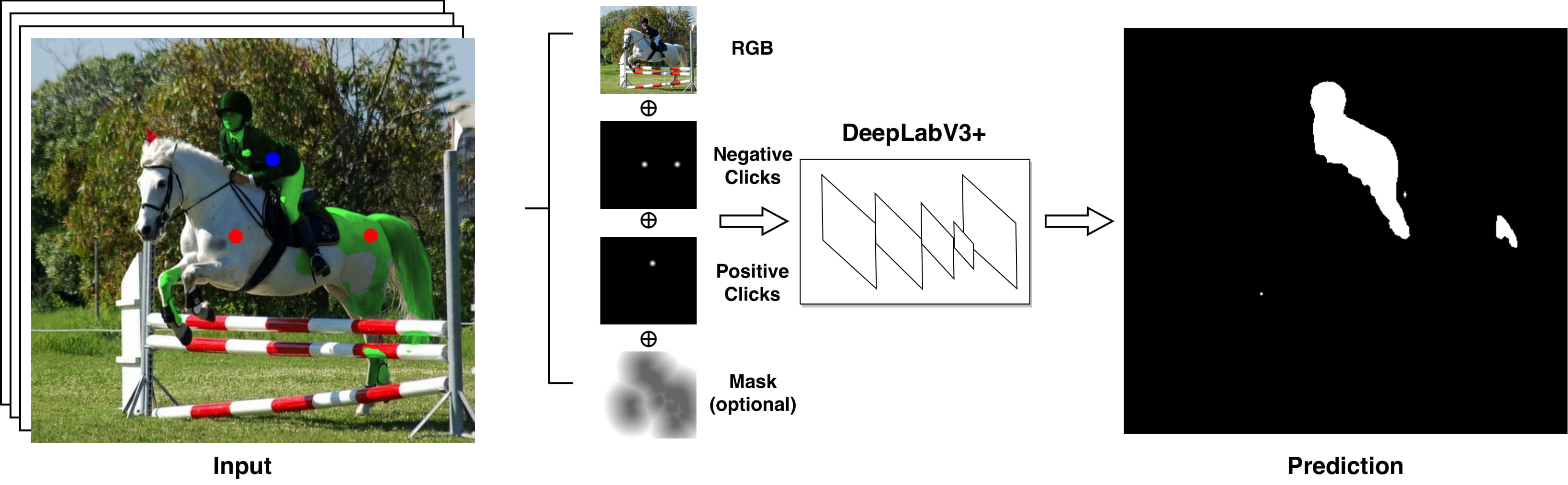
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
