
Profile

|
Publications
Direct Shot Correspondence Matching
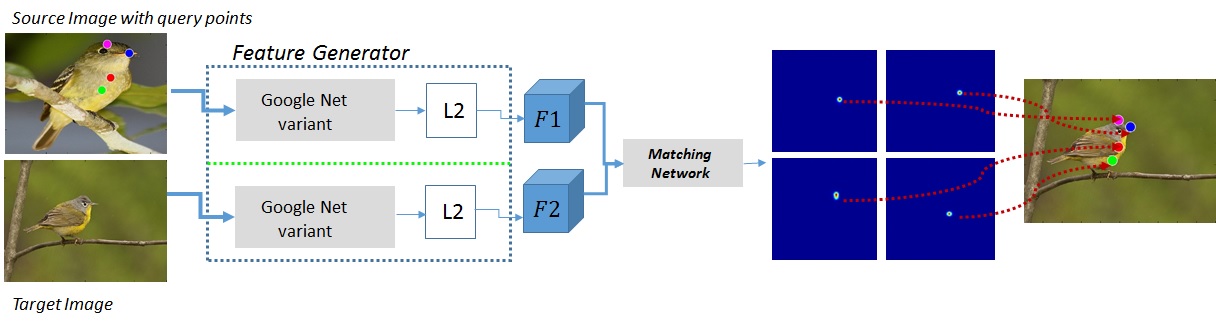
We propose a direct shot method for the task of correspondence matching. Instead of minimizing a loss based on positive and negative pairs, which requires hard-negative mining step for training and nearest neighbor search step for inference, we propose a novel similarity heatmap generator that makes these additional steps obsolete. The similarity heatmap generator efficiently generates peaked similarity heatmaps over the target image for all the query keypoints in a single pass. The matching network can be appended to any standard deep network architecture to make it end-to-end trainable with N-pairs based metric learning and achieves superior performance. We evaluate the proposed method on various correspondence matching datasets and achieve state-of-the-art performance.
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline

TL;DR: Detection+Tracking+{head orientation,skeleton} analysis. Smooth per-track enables filtering outliers as well as a "free flight" mode where expensive analysis modules are run with a stride, dramatically increasing runtime performance at almost no loss of prediction quality.
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction.
In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules’ observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called “free-flight” mode, where the analysis of a person attribute only relies on the filter’s predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.
@article{BreuersBeyer2018Arxiv,
title = {{Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline}},
author = {Breuers*, Stefan and Beyer*, Lucas and Rafi, Umer and Leibe, Bastian},
journal = {arXiv preprint arXiv:TBD},
year = {2018}
}
An Efficient Convolutional Network for Human Pose Estimation
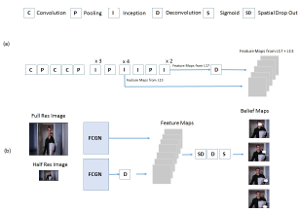
In recent years, human pose estimation has greatly benefited from deep learning and huge gains in performance have been achieved. The trend to maximise the accuracy on benchmarks, however, resulted in computationally expensive deep network architectures that require expensive hardware and pre-training on large datasets. This makes it difficult to compare different methods and to reproduce existing results. We therefore propose in this work an efficient deep network architecture that can be efficiently trained on mid-range GPUs without the need of any pre-training. Despite of the low computational requirements of our network, it is on par with much more complex models on popular benchmarks for human pose estimation.
A Fixed-Dimensional 3D Shape Representation for Matching Partially Observed Objects in Street Scenes
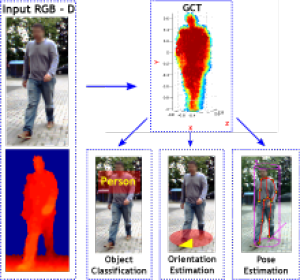
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
A Semantic Occlusion Model for Human Pose Estimation from a Single Depth image

Human pose estimation from depth data has made significant progress in recent years and commercial sensors estimate human poses in real-time. However, state-of-theart methods fail in many situations when the humans are partially occluded by objects. In this work, we introduce a semantic occlusion model that is incorporated into a regression forest approach for human pose estimation from depth data. The approach exploits the context information of occluding objects like a table to predict the locations of occluded joints. In our experiments on synthetic and real data, we show that our occlusion model increases the joint estimation accuracy and outperforms the commercial Kinect 2 SDK for occluded joints.
SPENCER: A Socially Aware Service Robot for Passenger Guidance and Help in Busy Airports

We present an ample description of a socially compliant mobile robotic platform, which is developed in the EU-funded project SPENCER. The purpose of this robot is to assist, inform and guide passengers in large and busy airports. One particular aim is to bring travellers of connecting flights conveniently and efficiently from their arrival gate to the passport control. The uniqueness of the project stems from the strong demand of service robots for this application with a large potential impact for the aviation industry on one side, and on the other side from the scientific advancements in social robotics, brought forward and achieved in SPENCER. The main contributions of SPENCER are novel methods to perceive, learn, and model human social behavior and to use this knowledge to plan appropriate actions in real- time for mobile platforms. In this paper, we describe how the project advances the fields of detection and tracking of individuals and groups, recognition of human social relations and activities, normative human behavior learning, socially-aware task and motion planning, learning socially annotated maps, and conducting empir- ical experiments to assess socio-psychological effects of normative robot behaviors.
@article{triebel2015spencer,
title={SPENCER: a socially aware service robot for passenger guidance and help in busy airports},
author={Triebel, Rudolph and Arras, Kai and Alami, Rachid and Beyer, Lucas and Breuers, Stefan and Chatila, Raja and Chetouani, Mohamed and Cremers, Daniel and Evers, Vanessa and Fiore, Michelangelo and Hung, Hayley and Islas Ramírez, Omar A. and Joosse, Michiel and Khambhaita, Harmish and Kucner, Tomasz and Leibe, Bastian and Lilienthal, Achim J. and Linder, Timm and Lohse, Manja and Magnusson, Martin and Okal, Billy and Palmieri, Luigi and Rafi, Umer and Rooij, Marieke van and Zhang, Lu},
journal={Field and Service Robotics (FSR)
year={2015},
publisher={University of Toronto}
}
