
Publications
Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
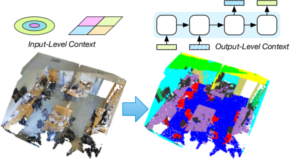
Deep learning approaches have made tremendous progress in the field of semantic segmentation over the past few years. However, most current approaches operate in the 2D image space. Direct semantic segmentation of unstructured 3D point clouds is still an open research problem. The recently proposed PointNet architecture presents an interesting step ahead in that it can operate on unstructured point clouds, achieving decent segmentation results. However, it subdivides the input points into a grid of blocks and processes each such block individually. In this paper, we investigate the question how such an architecture can be extended to incorporate larger-scale spatial context. We build upon PointNet and propose two extensions that enlarge the receptive field over the 3D scene. We evaluate the proposed strategies on challenging indoor and outdoor datasets and show improved results in both scenarios.
» Show BibTeX
@inproceedings{3dsemseg_ICCVW17,
author = {Francis Engelmann and
Theodora Kontogianni and
Alexander Hermans and
Bastian Leibe},
title = {Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} International Conference on Computer Vision, 3DRMS Workshop, {ICCV}},
year = {2017}
}
Online Adaptation of Convolutional Neural Networks for Video Object Segmentation

We tackle the task of semi-supervised video object segmentation, i.e. segmenting the pixels belonging to an object in the video using the ground truth pixel mask for the first frame. We build on the recently introduced one-shot video object segmentation (OSVOS) approach which uses a pretrained network and fine-tunes it on the first frame. While achieving impressive performance, at test time OSVOS uses the fine-tuned network in unchanged form and is not able to adapt to large changes in object appearance. To overcome this limitation, we propose Online Adaptive Video Object Segmentation (OnAVOS) which updates the network online using training examples selected based on the confidence of the network and the spatial configuration. Additionally, we add a pretraining step based on objectness, which is learned on PASCAL. Our experiments show that both extensions are highly effective and improve the state of the art on DAVIS to an intersection-over-union score of 85.7%.
@inproceedings{voigtlaender17BMVC,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for Video Object Segmentation},
booktitle = {BMVC},
year = {2017}
}
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
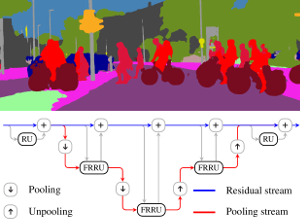
Semantic image segmentation is an essential component of modern autonomous driving systems, as an accurate understanding of the surrounding scene is crucial to navigation and action planning. Current state-of-the-art approaches in semantic image segmentation rely on pre-trained networks that were initially developed for classifying images as a whole. While these networks exhibit outstanding recognition performance (i.e., what is visible?), they lack localization accuracy (i.e., where precisely is something located?). Therefore, additional processing steps have to be performed in order to obtain pixel-accurate segmentation masks at the full image resolution. To alleviate this problem we propose a novel ResNet-like architecture that exhibits strong localization and recognition performance. We combine multi-scale context with pixel-level accuracy by using two processing streams within our network: One stream carries information at the full image resolution, enabling precise adherence to segment boundaries. The other stream undergoes a sequence of pooling operations to obtain robust features for recognition. The two streams are coupled at the full image resolution using residuals. Without additional processing steps and without pre-training, our approach achieves an intersection-over-union score of 71.8% on the Cityscapes dataset.
» Show BibTeX
@inproceedings{Pohlen2017CVPR,
title = {{Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes}},
author = {Pohlen, Tobias and Hermans, Alexander and Mathias, Markus and Leibe, Bastian},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'17)}},
year = {2017}
}
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
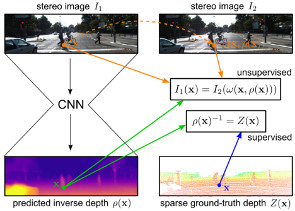
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-the-art methods.
» Show BibTeX
@inproceedings{kuznietsov2017_semsupdepth,
title = {Semi-Supervised Deep Learning for Monocular Depth Map Prediction},
author = {Kuznietsov, Yevhen and St\"uckler, J\"org and Leibe, Bastian},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Combined Image- and World-Space Tracking in Traffic Scenes

Tracking in urban street scenes plays a central role in autonomous systems such as self-driving cars. Most of the current vision-based tracking methods perform tracking in the image domain. Other approaches, e.g. based on LIDAR and radar, track purely in 3D. While some vision-based tracking methods invoke 3D information in parts of their pipeline, and some 3D-based methods utilize image-based information in components of their approach, we propose to use image- and world-space information jointly throughout our method. We present our tracking pipeline as a 3D extension of image-based tracking. From enhancing the detections with 3D measurements to the reported positions of every tracked object, we use world- space 3D information at every stage of processing. We accomplish this by our novel coupled 2D-3D Kalman filter, combined with a conceptually clean and extendable hypothesize-and-select framework. Our approach matches the current state-of-the-art on the official KITTI benchmark, which performs evaluation in the 2D image domain only. Further experiments show significant improvements in 3D localization precision by enabling our coupled 2D-3D tracking.
@inproceedings{Osep17ICRA,
title={Combined Image- and World-Space Tracking in Traffic Scenes},
author={O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2017}
}
Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
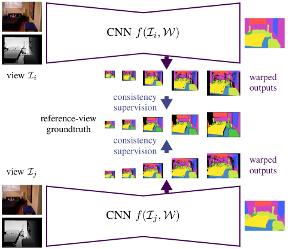
Visual scene understanding is an important capability that enables robots to purposefully act in their environment. In this paper, we propose a novel deep neural network approach to predict semantic segmentation from RGB-D sequences. The key innovation is to train our network to predict multi-view consistent semantics in a self-supervised way. At test time, its semantics predictions can be fused more consistently in semantic keyframe maps than predictions of a network trained on individual views. We base our network architecture on a recent single-view deep learning approach to RGB and depth fusion for semantic object-class segmentation and enhance it with multi-scale loss minimization. We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training. At test time, predictions from multiple views are fused into keyframes. We propose and analyze several methods for enforcing multi-view consistency during training and testing. We evaluate the benefit of multi-view consistency training and demonstrate that pooling of deep features and fusion over multiple views outperforms single-view baselines on the NYUDv2 benchmark for semantic segmentation. Our end-to-end trained network achieves state-of-the-art performance on the NYUDv2 dataset in single-view segmentation as well as multi-view semantic fusion.
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@InProceedings{lingni17iros,
author = "Lingni Ma and J\"org St\"uckler and Christian Kerl and Daniel Cremers",
title = "Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras",
booktitle = "IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)",
year = "2017",
}
Keyframe-Based Visual-Inertial Online SLAM with Relocalization
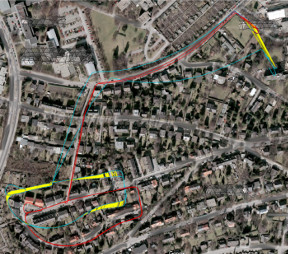
Complementing images with inertial measurements has become one of the most popular approaches to achieve highly accurate and robust real-time camera pose tracking. In this paper, we present a keyframe-based approach to visual-inertial simultaneous localization and mapping (SLAM) for monocular and stereo cameras. Our method is based on a real-time capable visual-inertial odometry method that provides locally consistent trajectory and map estimates. We achieve global consistency in the estimate through online loop-closing and non-linear optimization. Furthermore, our approach supports relocalization in a map that has been previously obtained and allows for continued SLAM operation. We evaluate our approach in terms of accuracy, relocalization capability and run-time efficiency on public benchmark datasets and on newly recorded sequences. We demonstrate state-of-the-art performance of our approach towards a visual-inertial odometry method in recovering the trajectory of the camera.
@article{Kasyanov2017_VISLAM,
title={{Keyframe-Based Visual-Inertial Online SLAM with Relocalization}},
author={Anton Kasyanov and Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle={{IEEE/RSJ} International Conference on Intelligent Robots and Systems {(IROS)}},
year={2017}
}
SAMP: Shape and Motion Priors for 4D Vehicle Reconstruction

Inferring the pose and shape of vehicles in 3D from a movable platform still remains a challenging task due to the projective sensing principle of cameras, difficult surface properties, e.g. reflections or transparency, and illumination changes between images. In this paper, we propose to use 3D shape and motion priors to regularize the estimation of the trajectory and the shape of vehicles in sequences of stereo images. We represent shapes by 3D signed distance functions and embed them in a low-dimensional manifold. Our optimization method allows for imposing a common shape across all image observations along an object track. We employ a motion model to regularize the trajectory to plausible object motions. We evaluate our method on the KITTI dataset and show state-of-the-art results in terms of shape reconstruction and pose estimation accuracy.
@inproceedings{EngelmannWACV17_samp,
author = {Francis Engelmann and J{\"{o}}rg St{\"{u}}ckler and Bastian Leibe},
title = {{SAMP:} Shape and Motion Priors for 4D Vehicle Reconstruction},
booktitle = {{IEEE} Winter Conference on Applications of Computer Vision,
{WACV}},
year = {2017}
}
DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data
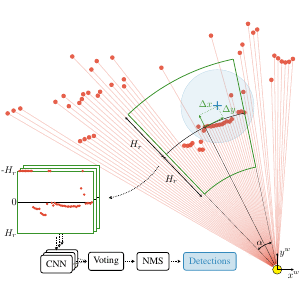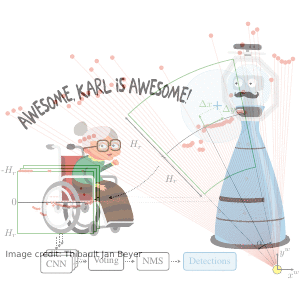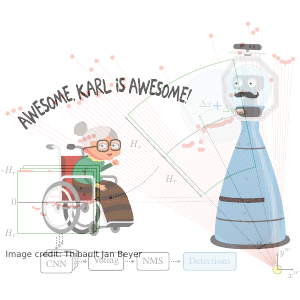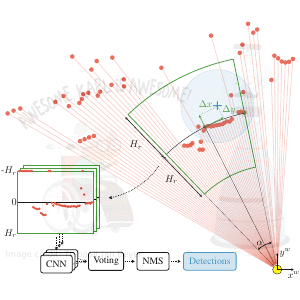
TL;DR: Collected & annotated laser detection dataset. Use window around each point to cast vote on detection center.
We introduce the DROW detector, a deep learning based detector for 2D range data. Laser scanners are lighting invariant, provide accurate range data, and typically cover a large field of view, making them interesting sensors for robotics applications. So far, research on detection in laser range data has been dominated by hand-crafted features and boosted classifiers, potentially losing performance due to suboptimal design choices. We propose a Convolutional Neural Network (CNN) based detector for this task. We show how to effectively apply CNNs for detection in 2D range data, and propose a depth preprocessing step and voting scheme that significantly improve CNN performance. We demonstrate our approach on wheelchairs and walkers, obtaining state of the art detection results. Apart from the training data, none of our design choices limits the detector to these two classes, though. We provide a ROS node for our detector and release our dataset containing 464k laser scans, out of which 24k were annotated.
» Show BibTeX
@article{BeyerHermans2016RAL,
title = {{DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data}},
author = {Beyer*, Lucas and Hermans*, Alexander and Leibe, Bastian},
journal = {{IEEE Robotics and Automation Letters (RA-L)}},
year = {2016}
}
Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation
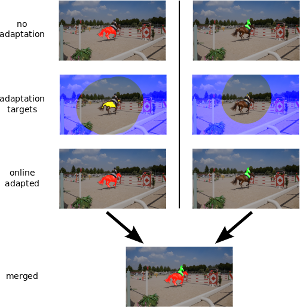
This paper describes our method used for the 2017 DAVIS Challenge on Video Object Segmentation [26]. The challenge’s task is to segment the pixels belonging to multiple objects in a video using the ground truth pixel masks, which are given for the first frame. We build on our recently proposed Online Adaptive Video Object Segmentation (OnAVOS) method which pretrains a convolutional neural network for objectness, fine-tunes it on the first frame, and further updates the network online while processing the video. OnAVOS selects confidently predicted foreground pixels as positive training examples and pixels, which are far away from the last assumed object position as negative examples. While OnAVOS was designed to work with a single object, we extend it to handle multiple objects by combining the predictions of multiple single-object runs. We introduce further extensions including upsampling layers which increase the output resolution. We achieved the fifth place out of 22 submissions to the competition.
@article{voigtlaender17DAVIS,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation},
journal = {The 2017 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2017}
}
From Monocular SLAM to Autonomous Drone Exploration
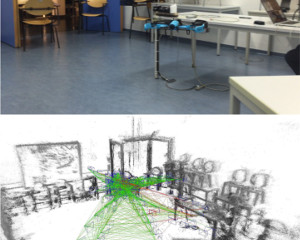
Micro aerial vehicles (MAVs) are strongly limited in their payload and power capacity. In order to implement autonomous navigation, algorithms are therefore desirable that use sensory equipment that is as small, low-weight, and low- power consuming as possible. In this paper, we propose a method for autonomous MAV navigation and exploration using a low-cost consumer-grade quadrocopter equipped with a monocular camera. Our vision-based navigation system builds on LSD-SLAM which estimates the MAV trajectory and a semi-dense reconstruction of the environment in real-time. Since LSD-SLAM only determines depth at high gradient pixels, texture-less areas are not directly observed. We propose an obstacle mapping and exploration approach that takes this property into account. In experiments, we demonstrate our vision-based autonomous navigation and exploration system with a commercially available Parrot Bebop MAV.
» Show BibTeX
@inproceedings{stumberg2017_mavexplore,
author={Lukas von Stumberg and Vladyslav Usenko and Jakob Engel and J\"org St\"uckler and Daniel Cremers},
title={From Monoular {SLAM} to Autonomous Drone Exploration},
booktitle = {Accepted for the European Conference on Mobile Robots (ECMR)},
year = {2017},
}
3D Semantic Segmentation of Modular Furniture using rjMCMC
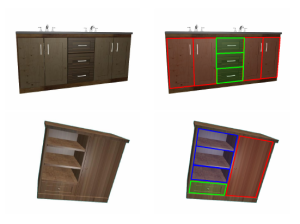
In this paper we propose a novel approach to identify and label the structural elements of furniture e.g. wardrobes, cabinets etc. Given a furniture item, the subdivision into its structural components like doors, drawers and shelves is difficult as the number of components and their spatial arrangements varies severely. Furthermore, structural elements are primarily distinguished by their function rather than by unique color or texture based appearance features. It is therefore difficult to classify them, even if their correct spatial extent were known. In our approach we jointly estimate the number of functional units, their spatial structure, and their corresponding labels by using reversible jump MCMC (rjMCMC), a method well suited for optimization on spaces of varying dimensions (the number of structural elements). Optionally, our system permits to invoke depth information e.g. from RGB-D cameras, which are already frequently mounted on mobile robot platforms. We show a considerable improvement over a baseline method even without using depth data, and an additional performance gain when depth input is enabled.
@inproceedings{badamiWACV17,
title={3D Semantic Segmentation of Modular Furniture using rjMCMC
},
author={Badami, Ishrat and Tom, Manu and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2017}
}
Towards a Principled Integration of Multi-Camera Re-Identification and Tracking through Optimal Bayes Filters
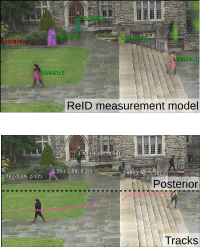
TL;DR: Explorative paper. Learn a Triplet-ReID net, embed the full image. Keep embeddings of known tracks, correlate them with image embeddings and use that as measurement model in a Bayesian filtering tracker. MOT score is mediocre, but framework is theoretically pleasing.
With the rise of end-to-end learning through deep learning, person detectors and re-identification (ReID) models have recently become very strong. Multi-camera multi-target (MCMT) tracking has not fully gone through this transformation yet. We intend to take another step in this direction by presenting a theoretically principled way of integrating ReID with tracking formulated as an optimal Bayes filter. This conveniently side-steps the need for data-association and opens up a direct path from full images to the core of the tracker. While the results are still sub-par, we believe that this new, tight integration opens many interesting research opportunities and leads the way towards full end-to-end tracking from raw pixels.
@article{BeyerBreuers2017Arxiv,
author = {Lucas Beyer and
Stefan Breuers and
Vitaly Kurin and
Bastian Leibe},
title = {{Towards a Principled Integration of Multi-Camera Re-Identification
and Tracking through Optimal Bayes Filters}},
journal = {{2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}},
year = {2017},
pages ={1444-1453},
}
In Defense of the Triplet Loss for Person Re-Identification

TL;DR: Use triplet loss, hard-mining inside mini-batch performs great, is similar to offline semi-hard mining but much more efficient.
In the past few years, the field of computer vision has gone through a revolution fueled mainly by the advent of large datasets and the adoption of deep convolutional neural networks for end-to-end learning. The person re-identification subfield is no exception to this, thanks to the notable publication of the Market-1501 and MARS datasets and several strong deep learning approaches. Unfortunately, a prevailing belief in the community seems to be that the triplet loss is inferior to using surrogate losses (classification, verification) followed by a separate metric learning step. We show that, for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms any other published method by a large margin.
@article{HermansBeyer2017Arxiv,
title = {{In Defense of the Triplet Loss for Person Re-Identification}},
author = {Hermans*, Alexander and Beyer*, Lucas and Leibe, Bastian},
journal = {arXiv preprint arXiv:1703.07737},
year = {2017}
}
Previous Year (2016)
