
Publications
PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation
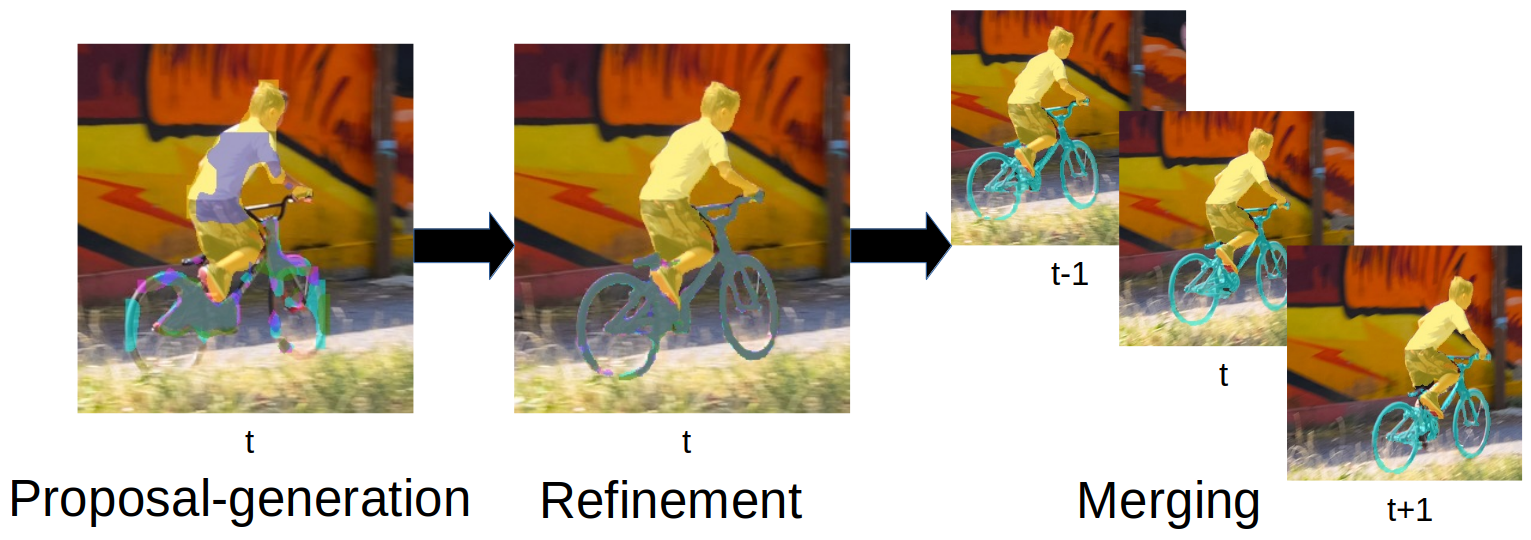
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposalgeneration, Refinement and Merging for Video Object Segmentation). Our method separates this problem into two steps, first generating a set of accurate object segmentation mask proposals for each video frame and then selecting and merging these proposals into accurate and temporally consistent pixel-wise object tracks over a video sequence in a way which is designed to specifically tackle the difficult challenges involved with segmenting multiple objects across a video sequence. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object egmentation benchmark with a J & F mean score of 71.6 on the test-dev dataset, and achieves first place in both the DAVIS 2018 Video Object Segmentation Challenge and the YouTube-VOS 1st Large-scale Video Object Segmentation Challenge.
@inproceedings{luiten2018premvos,
title={PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation},
author={Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
booktitle={Asian Conference on Computer Vision},
year={2018}
}
Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking

The most common paradigm for vision-based multi-object tracking is tracking-by-detection, due to the availability of reliable detectors for several important object categories such as cars and pedestrians. However, future mobile systems will need a capability to cope with rich human-made environments, in which obtaining detectors for every possible object category would be infeasible. In this paper, we propose a model-free multi-object tracking approach that uses a category-agnostic image segmentation method to track objects. We present an efficient segmentation mask-based tracker which associates pixel-precise masks reported by the segmentation. Our approach can utilize semantic information whenever it is available for classifying objects at the track level, while retaining the capability to track generic unknown objects in the absence of such information. We demonstrate experimentally that our approach achieves performance comparable to state-of-the-art tracking-by-detection methods for popular object categories such as cars and pedestrians. Additionally, we show that the proposed method can discover and robustly track a large variety of other objects.
@article{Osep18ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Voigtlaender, Paul and Leibe, Bastian},
title = {Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking},
journal = {ICRA},
year = {2018}
}
Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds
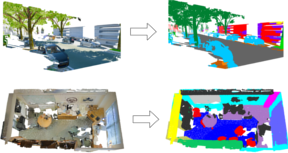
In this paper, we present a deep learning architecture which addresses the problem of 3D semantic segmentation of unstructured point clouds. Compared to previous work, we introduce grouping techniques which define point neighborhoods in the initial world space and the learned feature space. Neighborhoods are important as they allow to compute local or global point features depending on the spatial extend of the neighborhood. Additionally, we incorporate dedicated loss functions to further structure the learned point feature space: the pairwise distance loss and the centroid loss. We show how to apply these mechanisms to the task of 3D semantic segmentation of point clouds and report state-of-the-art performance on indoor and outdoor datasets.
@inproceedings{3dsemseg_ECCVW18,
author = {Francis Engelmann and
Theodora Kontogianni and
Jonas Schult and
Bastian Leibe},
title = {Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} European Conference on Computer Vision, GMDL Workshop, {ECCV}},
year = {2018}
}
MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
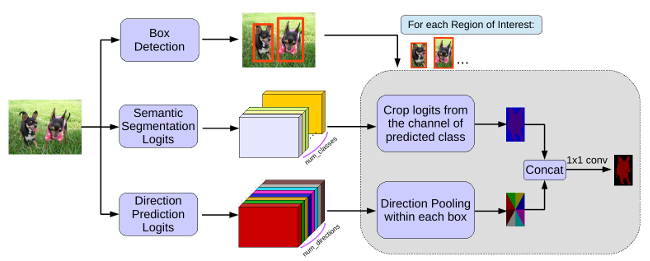
In this work, we tackle the problem of instance segmentation, the task of simultaneously solving object detection and semantic segmentation. Towards this goal, we present a model, called MaskLab, which produces three outputs: box detection, semantic segmentation, and direction prediction. Building on top of the Faster-RCNN object detector, the predicted boxes provide accurate localization of object instances. Within each region of interest, MaskLab performs foreground/background segmentation by combining semantic and direction prediction. Semantic segmentation assists the model in distinguishing between objects of different semantic classes including background, while the direction prediction, estimating each pixel's direction towards its corresponding center, allows separating instances of the same semantic class. Moreover, we explore the effect of incorporating recent successful methods from both segmentation and detection (i.e. atrous convolution and hypercolumn). Our proposed model is evaluated on the COCO instance segmentation benchmark and shows comparable performance with other state-of-art models.
@article{Chen18CVPR,
title = {{MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features}},
author = {Chen, Liang-Chieh and Hermans, Alexander and Papandreou, George and Schroff, Florian and Wang, Peng and Adam, Hartwig},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18)}},,
year = {2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018
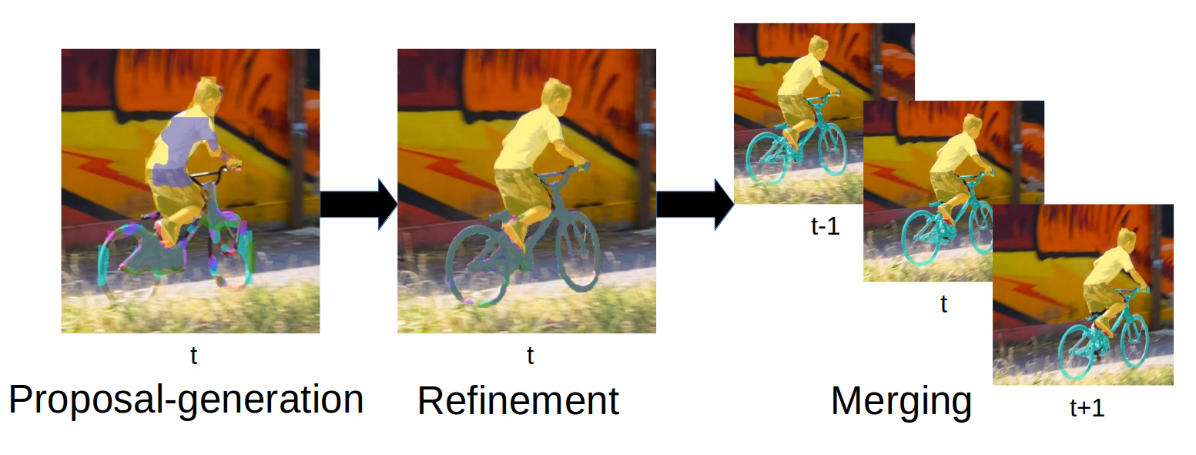
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposal-generation, Refinement and Merging for Video Object Segmentation). This method involves generating coarse object proposals using a Mask R-CNN like object detector, followed by a refinement network that produces accurate pixel masks for each proposal. We then select and link these proposals over time using a merging algorithm that takes into account an objectness score, the optical flow warping, and a Re-ID feature embedding vector for each proposal. We adapt our networks to the target video domain by fine-tuning on a large set of augmented images generated from the first-frame ground truth. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object segmentation benchmark and achieves first place in the DAVIS 2018 Video Object Segmentation Challenge with a mean of J & F score of 74.7.
@article{Luiten18CVPRW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018}},
journal = {The 2018 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2018}
}
How Robust is 3D Human Pose Estimation to Occlusion?
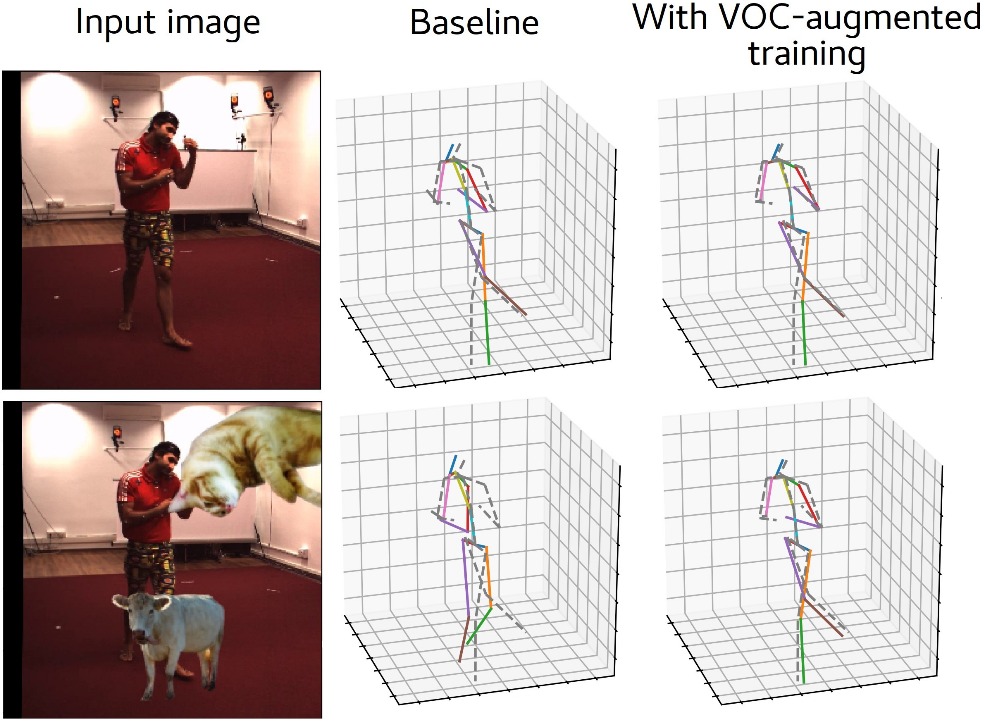
Occlusion is commonplace in realistic human-robot shared environments, yet its effects are not considered in standard 3D human pose estimation benchmarks. This leaves the question open: how robust are state-of-the-art 3D pose estimation methods against partial occlusions? We study several types of synthetic occlusions over the Human3.6M dataset and find a method with state-of-the-art benchmark performance to be sensitive even to low amounts of occlusion. Addressing this issue is key to progress in applications such as collaborative and service robotics. We take a first step in this direction by improving occlusion-robustness through training data augmentation with synthetic occlusions. This also turns out to be an effective regularizer that is beneficial even for non-occluded test cases.
@inproceedings{Sarandi18IROSW,
title={How Robust is {3D} Human Pose Estimation to Occlusion?},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems Workshops (IROSW)},
year={2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018
We evaluate our PReMVOS algorithm [1]2 on the new YouTube-VOS dataset [3] for the task of semi-supervised video object segmentation (VOS). This task consists of automatically generating accurate and consistent pixel masks for multiple objects in a video sequence, given the object’s first-frame ground truth annotations. The new YouTube-VOS dataset and the corresponding challenge, the 1st Large-scale Video Object Segmentation Challenge, provide a much larger scale evaluation than any previous VOS benchmarks. Our method achieves the best results in the 2018 Large-scale Video Object Segmentation Challenge with a J &F overall mean score over both known and unknown categories of 72.2.
@article{Luiten18ECCVW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018}},
journal = {The 1st Large-scale Video Object Segmentation Challenge - ECCV Workshops},
year = {2018}
}
Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation
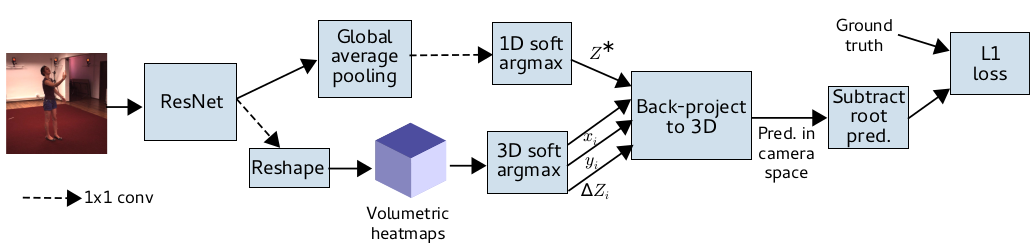
In this paper we present our winning entry at the 2018 ECCV PoseTrack Challenge on 3D human pose estimation. Using a fully-convolutional backbone architecture, we obtain volumetric heatmaps per body joint, which we convert to coordinates using soft-argmax. Absolute person center depth is estimated by a 1D heatmap prediction head. The coordinates are back-projected to 3D camera space, where we minimize the L1 loss. Key to our good results is the training data augmentation with randomly placed occluders from the Pascal VOC dataset. In addition to reaching first place in the Challenge, our method also surpasses the state-of-the-art on the full Human3.6M benchmark when considering methods that use no extra pose datasets in training. Code for applying synthetic occlusions is availabe at https://github.com/isarandi/synthetic-occlusion.
» Show BibTeX
@article{Sarandi18synthocc,
author = {S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
title = {Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 {ECCV PoseTrack Challenge} on {3D} Human Pose Estimation},
journal={arXiv preprint arXiv:1809.04987},
year = {2018}
}
Deep Person Detection in 2D Range Data
TL;DR: Extend the DROW dataset to persons, extend the method to include short temporal context, and extensively benchmark all available methods.
Detecting humans is a key skill for mobile robots and intelligent vehicles in a large variety of applications. While the problem is well studied for certain sensory modalities such as image data, few works exist that address this detection task using 2D range data. However, a widespread sensory setup for many mobile robots in service and domestic applications contains a horizontally mounted 2D laser scanner. Detecting people from 2D range data is challenging due to the speed and dynamics of human leg motion and the high levels of occlusion and self-occlusion particularly in crowds of people. While previous approaches mostly relied on handcrafted features, we recently developed the deep learning based wheelchair and walker detector DROW. In this paper, we show the generalization to people, including small modifications that significantly boost DROW's performance. Additionally, by providing a small, fully online temporal window in our network, we further boost our score. We extend the DROW dataset with person annotations, making this the largest dataset of person annotations in 2D range data, recorded during several days in a real-world environment with high diversity. Extensive experiments with three current baseline methods indicate it is a challenging dataset, on which our improved DROW detector beats the current state-of-the-art.
@article{Beyer2018RAL,
title = {{Deep Person Detection in 2D Range Data}},
author = {Beyer, Lucas and Hermans, Alexander and Linder, Timm and Arras, Kai Oliver and Leibe, Bastian},
journal = {IEEE Robotics and Automation Letters},
volume = {3},
number = {3},
pages = {2726--2733}
year = {2018}
}
Towards Large-Scale Video Video Object Mining
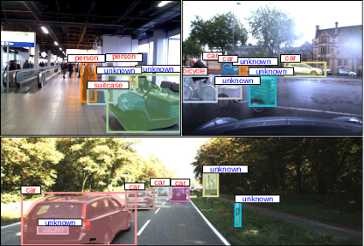
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
@article{OsepVoigtlaender18ECCVW,
title={Towards Large-Scale Video Object Mining},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={ECCV 2018 Workshop on Interactive and Adaptive Learning in an Open World},
year={2018}
}
Direct Shot Correspondence Matching
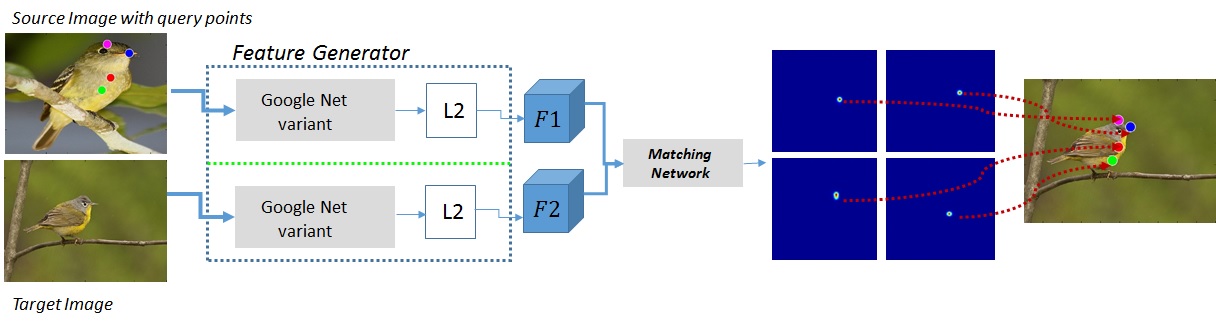
We propose a direct shot method for the task of correspondence matching. Instead of minimizing a loss based on positive and negative pairs, which requires hard-negative mining step for training and nearest neighbor search step for inference, we propose a novel similarity heatmap generator that makes these additional steps obsolete. The similarity heatmap generator efficiently generates peaked similarity heatmaps over the target image for all the query keypoints in a single pass. The matching network can be appended to any standard deep network architecture to make it end-to-end trainable with N-pairs based metric learning and achieves superior performance. We evaluate the proposed method on various correspondence matching datasets and achieve state-of-the-art performance.
Iteratively Trained Interactive Segmentation
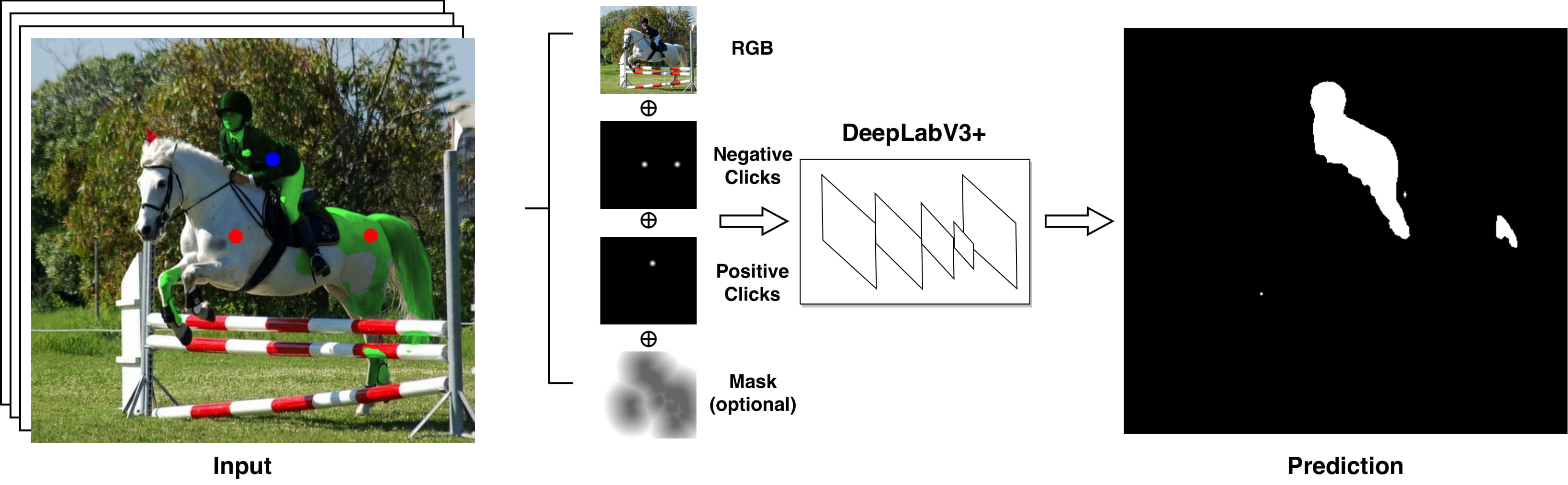
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline

TL;DR: Detection+Tracking+{head orientation,skeleton} analysis. Smooth per-track enables filtering outliers as well as a "free flight" mode where expensive analysis modules are run with a stride, dramatically increasing runtime performance at almost no loss of prediction quality.
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction.
In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules’ observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called “free-flight” mode, where the analysis of a person attribute only relies on the filter’s predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.
@article{BreuersBeyer2018Arxiv,
title = {{Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline}},
author = {Breuers*, Stefan and Beyer*, Lucas and Rafi, Umer and Leibe, Bastian},
journal = {arXiv preprint arXiv:TBD},
year = {2018}
}
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
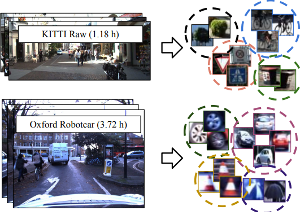
We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.
@article{OsepVoigtlaender18arxiv,
title={Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={arXiv preprint arXiv:1712.08832},
year={2018}
}
Previous Year (2017)
