
Publications
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
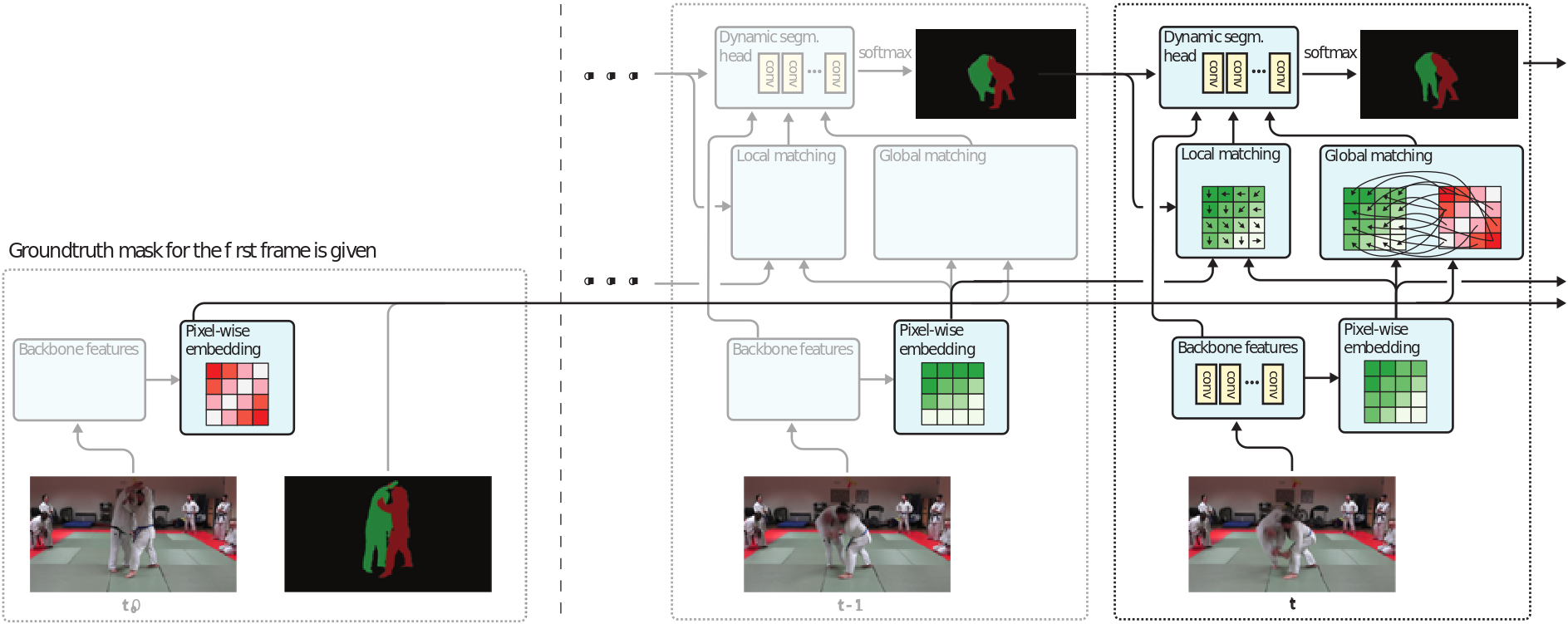
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
@inproceedings{Voigtlaender19CVPR,
title={{FEELVOS}: Fast End-to-End Embedding Learning for Video Object Segmentation},
author={Paul Voigtlaender and Yuning Chai and Florian Schroff and Hartwig Adam and Bastian Leibe and Liang-Chieh Chen},
booktitle={CVPR},
year={2019}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
» Show BibTeX
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects

Methods tackling multi-object tracking need to estimate the number of targets in the sensing area as well as to estimate their continuous state. While the majority of existing methods focus on data association, precise state (3D pose) estimation is often only coarsely estimated by approximating targets with centroids or (3D) bounding boxes. However, in automotive scenarios, motion perception of surrounding agents is critical and inaccuracies in the vehicle close-range can have catastrophic consequences. In this work, we focus on precise 3D track state estimation and propose a learning-based approach for object-centric relative motion estimation of partially observed objects. Instead of approximating targets with their centroids, our approach is capable of utilizing noisy 3D point segments of objects to estimate their motion. To that end, we propose a simple, yet effective and efficient network, AlignNet-3D, that learns to align point clouds. Our evaluation on two different datasets demonstrates that our method outperforms computationally expensive, global 3D registration methods while being significantly more efficient.
@inproceedings{Gross193DV,
title = {AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects},
author = {Johannes Gro\ss and Aljo\v{s}a O\v{s}ep and Bastian Leibe},
booktitle = {International Conference on 3D Vision {(3DV)}},
year = {2019}
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
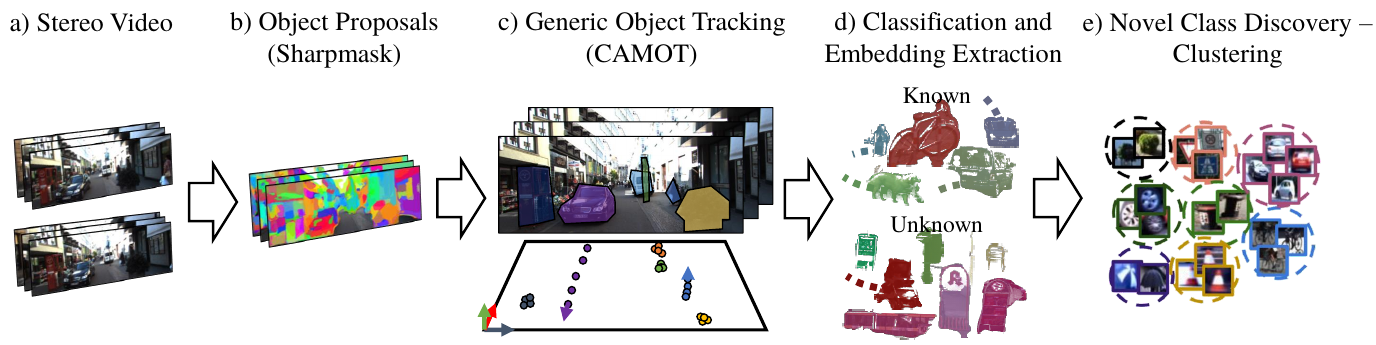
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
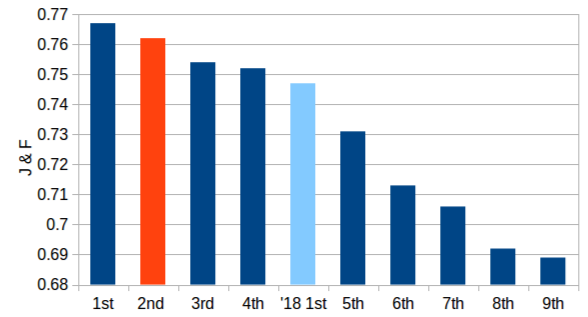
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
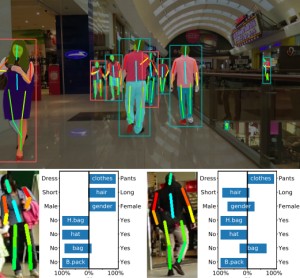
We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
@inproceedings{Pfeiffer19GCPR,
title = {Visual Person Understanding Through Multi-task and Multi-dataset Learning},
author = {Kilian Pfeiffer and Alexander Hermans and Istv\'{a}n S\'{a}r\'{a}ndi and Mark Weber and Bastian Leibe},
booktitle = {German Conference on Pattern Recognition (GCPR)},
date = {2019}
}
Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.
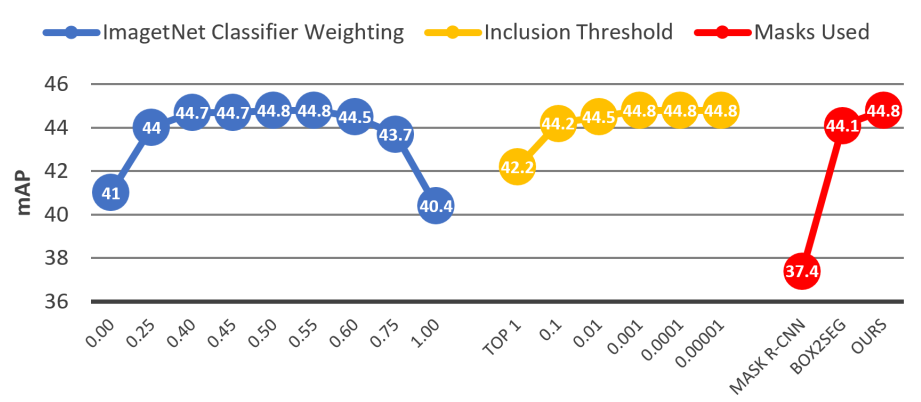
Video Instance Segmentation (VIS) is the task of localizing all objects in a video, segmenting them, tracking them throughout the video and classifying them into a set of predefined classes. In this work, divide VIS into these four parts: detection, segmentation, tracking and classification. We then develop algorithms for performing each of these four sub tasks individually, and combine these into a complete solution for VIS. Our solution is an adaptation of UnOVOST, the current best performing algorithm for Unsupervised Video Object Segmentation, to this VIS task. We benchmark our algorithm on the 2019 YouTube-VIS Challenge, where we obtain first place with an mAP score of 46.7%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Philip Torr and Bastian Leibe},
title = {{Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixelmasks for salient objects in a video sequence and of track-ing these objects consistently through time, without any in-formation about which objects should be tracked. Towardssolving this task, we present UnOVOST (Unsupervised Of-fline Video Object Segmentation and Tracking) as a simpleand generic algorithm which is able to track a large varietyof objects. This algorithm hierarchically builds up tracksin five stages. First, object proposal masks are generatedusing Mask R-CNN. Second, masks are sub-selected andclipped so that they do not overlap in the image domain.Third, tracklets are generated by grouping object propos-als that are strongly temporally consistent with each otherunder optical flow warping. Fourth, tracklets are mergedinto long-term consistent object tracks using their temporalconsistency and an appearance similarity metric calculatedusing an object re-identification network. Finally, the mostsalient object tracks are selected based on temporal tracklength and detection confidence scores. We evaluate ourapproach on the DAVIS 2017 Unsupervised dataset and ob-tain state-of-the-art performance with a meanJ&Fscoreof 58% on the test-dev benchmark. Our approach furtherachieves first place in the DAVIS 2019 Unsupervised VideoObject Segmentation Challenge with a mean ofJ&Fscoreof 56.4% on the test-challenge benchmark.
@article{ZulfikarLuitenUnOVOST,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge},
author={Zulfikar, Idil Esen and Luiten, Jonathon and Leibe, Bastian}
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge
Video Object Segmentation is the task of tracking and segmenting objects in a video given the first-frame mask of objects to be tracked. There have been a number of different successful paradigms for tackling this task, from creating object proposals and linking them in time as in PReMVOS, to detecting objects to be tracked conditioned on the given first-frame as in BoLTVOS, and creating tracklets based on motion consistency before merging these into long-term tracks as in UnOVOST. In this paper we explore how these three different approaches can be combined into a novel Video Object Segmentation algorithm. We evaluate our approach on the 2019 Youtube-VOS challenge where we obtain 6th place with an overall score of 71.5%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
BoLTVOS: Box-Level Tracking for Video Object Segmentation

We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the first-frame bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
@article{VoigtlaenderLuiten19arxiv,
author = {Paul Voigtlaender and Jonathon Luiten and Bastian Leibe},
title = {{BoLTVOS: Box-Level Tracking for Video Object Segmentation}},
journal = {arXiv:1904.04552},
year = {2019}
}
3D-BEVIS: Birds-Eye-View Instance Segmentation
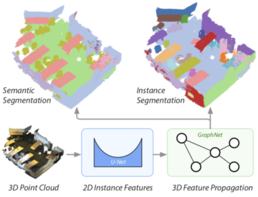
Recent deep learning models achieve impressive results on 3D scene analysis tasks by operating directly on unstructured point clouds. A lot of progress was made in the field of object classification and semantic segmentation. However, the task of instance segmentation is less explored. In this work, we present 3D-BEVIS, a deep learning framework for 3D semantic instance segmentation on point clouds. Following the idea of previous proposal-free instance segmentation approaches, our model learns a feature embedding and groups the obtained feature space into semantic instances. Current point-based methods scale linearly with the number of points by processing local sub-parts of a scene individually. However, to perform instance segmentation by clustering, globally consistent features are required. Therefore, we propose to combine local point geometry with global context information from an intermediate bird's-eye view representation.
@inproceedings{ElichGCPR19,
title = {{3D-BEVIS: Birds-Eye-View Instance Segmentation}},
author = {Elich, Cathrin and Engelmann, Francis and Schult, Jonas and Kontogianni, Theodora and Leibe, Bastian},
booktitle = {{German Conference on Pattern Recognition (GCPR)}},
year = {2019}
}
Previous Year (2018)
